Parallelism and Concurrency
The first computers were designed to do one thing at a time. A lot of their work was in the field of computational mathematics. As time went on, computers are needed to process inputs from a variety of sources. Some input as far away as distant galaxies. The consequence of this is that computer applications spend a lot of time idly waiting for responses.
Whether they be from a bus, an input, memory, computation, an API, or a remote resource. Another progression in computing was the move in Operating Systems away from a single-user terminal, to a multitasking Operating System. Applications needed to run in the background to listen and respond on the network and process inputs such as the mouse cursor. Multitasking was required way before modern multiple-core CPUs, so Operating Systems long could to share the system resources between multiple processes.
At the core of any Operating System is a registry of running processes. Each process will have an owner, and it can request resources, like memory or CPU. In the last chapter, you explored memory allocation. For a CPU, the process will request CPU time in the form of operations to be executed. The Operating System controls which process is using the CPU. It does this by allocating “CPU Time” and scheduling processes by a priority:
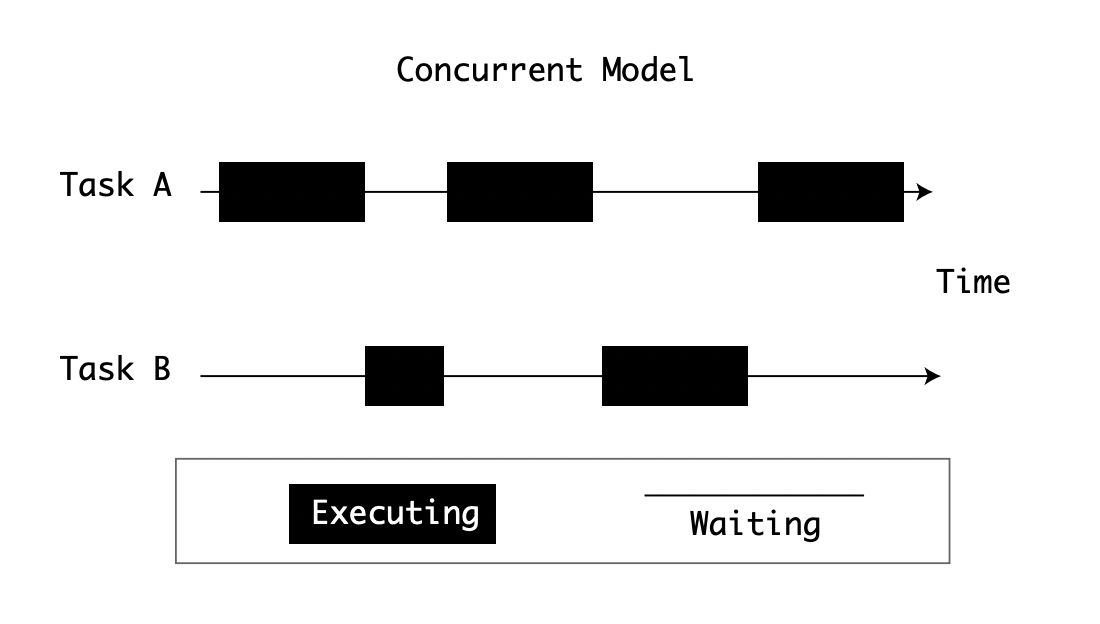
A single process may need to do multiple things at once. For example, if you use a word processor, it needs to check your spelling while you’re typing. Modern applications accomplish this by running multiple threads, concurrently, and handling their own resources.
Concurrency is an excellent solution to dealing with multitasking, but CPUs have their limits. Some high-performance computers deploy either multiple CPUs or multiple cores to spread tasks. Operating Systems provide a way of scheduling processes across multiple CPUs:
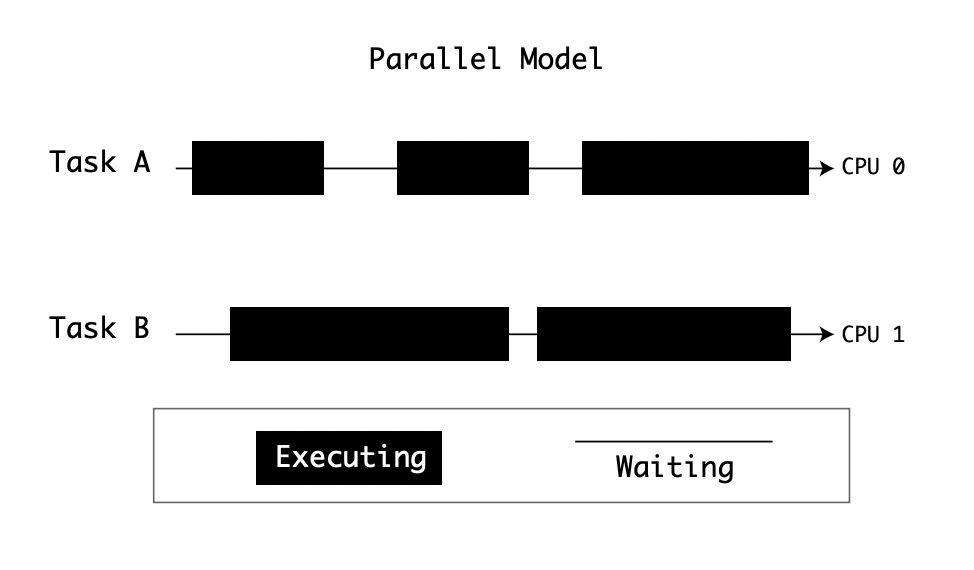
In summary,
- To have parallelism, you need multiple computational units. Computational units can be CPUs or Cores.
- To have concurrency, you need a way of scheduling tasks so that idle ones don’t lock the resources.
Many parts of CPython’s design abstract the complexity of Operating Systems to provide a simple API for developers. CPython’s approach to parallelism and concurrency is no exception.
Models of Parallelism and Concurrency
CPython offers many approaches to Parallelism and Concurrency. Your choice depends on several factors. There are also overlapping use cases across models as CPython has evolved.
You may find that for a particular problem, there are two or more concurrency implementations to choose from. Each with their own pros and cons.
The four bundled models with CPython are:
| Approach | Module | Concurrent | Parallel |
|---|---|---|---|
| Threading | threading |
Yes | No |
| Multiprocessing | multiprocessing |
Yes | Yes |
| Async | asyncio |
Yes | No |
| Subinterpreters | subinterpreters |
Yes | Yes |
The Structure of a Process
One of the tasks for an Operating System, like Windows, macOS, or Linux, is to control the running processes. These processes could be UI applications like a browser or IDE. They could also be background processes, like network services or OS services.
To control these processes, the OS provides an API to start a new process. When a process is created, it is registered by the Operating System so that it knows which processes are running. Processes are given a unique ID (PID). Depending on the Operating System, they have other properties.
POSIX processes have a minimum set of properties, registered in the Operating System:
- Controlling Terminal
- Current Working Directory
- Effective Group ID, Effective User ID
- File Descriptors, File Mode Creation Mask
- Process Group ID, Process ID
- Real Group ID, Real User ID
- Root Directory
You can see these attributes for running processes in macOS or Linux by running the ps command.
Note
The IEEE POSIX Standard (1003.1-2017) defines the interface and standard behaviors for processes and threads
Windows has a similar list of properties but sets its own standard. The Windows file permissions, directory structures, and process registry are very different from POSIX. Windows processes, represented by Win32_Process, can be queried in WMI, the Windows Management Interface runtime, or by using the Task Manager.
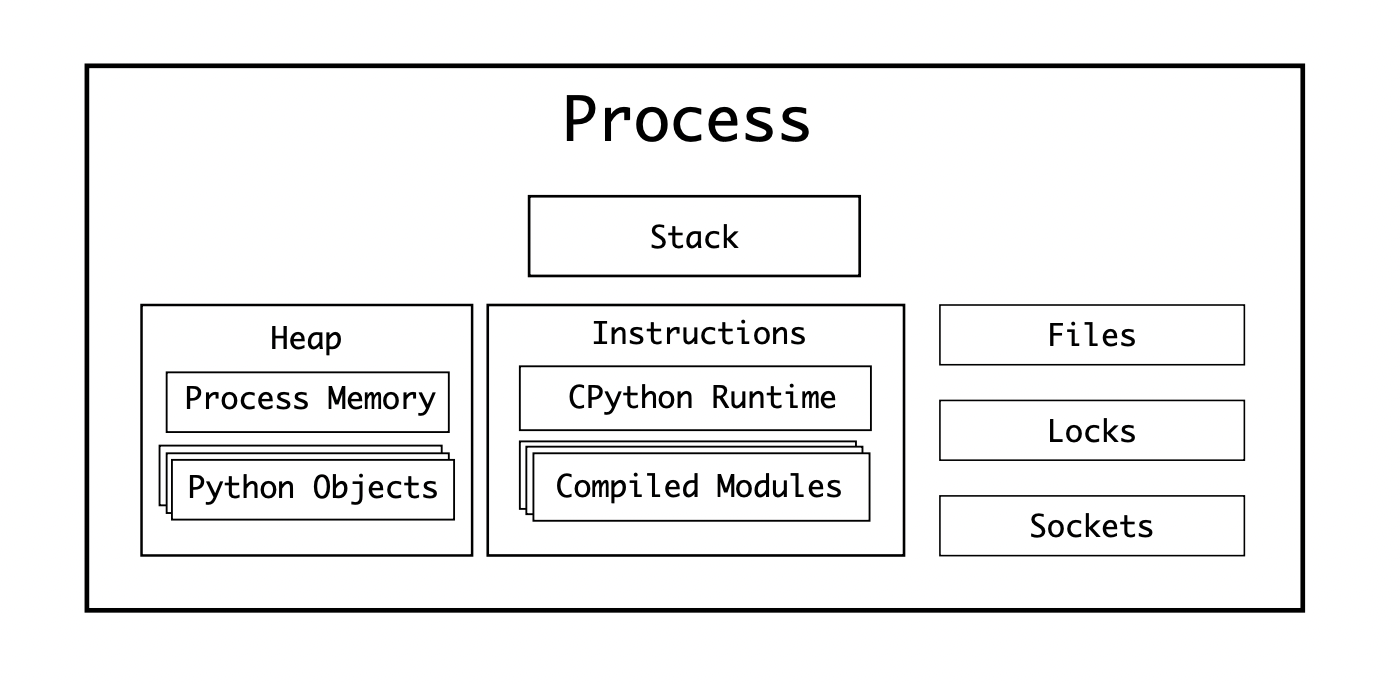
Once a process is started on an Operating System, it is given:
- A Stack of memory for calling subroutines
- A Heap (see Dynamic Memory Allocation in C)
- Access to Files, Locks, and Sockets on the Operating System
The CPU on your computer also keeps additional data when the process is executing, such as :
- Registers holding the current instruction being executed or any other data needed by the process for that instruction
- An Instruction Pointer, or Program Counter indicating which instruction in the program sequence is being executed
The CPython process comprises of the compiled CPython interpreter, and the compiled modules. These modules are loaded at runtime and converted into instructions by the CPython Evaluation Loop:
The program register and program counter point to a single instruction in the process. This means that only one instruction can be executing at any one time.
For CPython, this means that only one Python bytecode instruction can be executing at any one time.
There are two main approaches to allowing parallel execution of instructions in a process:
- Fork another process
- Spawn a thread
Now that you have reviewed what makes up a process. Next, you can explore forking and spawning child processes.
Multi-Process Parallelism
POSIX systems provide an API for any process to fork a child process. Forking processes is a low-level API call to the Operating System that can be made by any running process. When this call is made, the OS will clone all the attributes of the currently running process and create a new process. This clone operation includes the heap, register, and counter position of the parent process. The child process can read any variables from the parent process at the time of forking.
Forking a Process in POSIX
As an example, take the Fahrenheit to Celcius example application used at the beginning of Dynamic Memory Allocation in C. Adapt it to spawn a child process for each Fahrenheit value instead of calculating them in sequence. This is accomplished by using the fork() function. Each child process will continue operating from that point:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
static const double five_ninths = 5.0/9.0;
double celsius(double fahrenheit) {
return (fahrenheit - 32) * five_ninths;
}
int main(int argc, char** argv) {
if (argc != 2)
return -1;
int number = atoi(argv[1]);
for (int i = 1 ; i <= number ; i++ ) {
double f_value = 100 + (i*10);
pid_t child = fork();
if (child == 0) { // Is child process
double c_value = celsius(f_value);
printf("%f F is %f C (pid %d)n", f_value, c_value, getpid());
exit(0);
}
}
printf("Spawned %d processes from %dn", number, getpid());
return 0;
}
Running this on the command-line would give an output similar to:
./thread_celcius 4
110.000000 F is 43.333333 C (pid 57179)
120.000000 F is 48.888889 C (pid 57180)
Spawned 4 processes from 57178
130.000000 F is 54.444444 C (pid 57181)
140.000000 F is 60.000000 C (pid 57182)
The parent process (57178), spawned 4 processes. For each child process, it continued at the line child = fork(), where the resulting value of child is 0. It then completes the calculation, prints the value, and exits the process. Finally, the parent process outputs how many processes it spawned, and it’s own PID. The time taken for the 3rd and 4th child processes to complete was longer than it took for the parent process to complete. This is why the parent process prints the final output before the 3rd and 4th print their own.
A parent process can exit, with its own exit code before a child process. Child Processes will be added to a Process Group by the Operating System, making it easier to control all related processes:
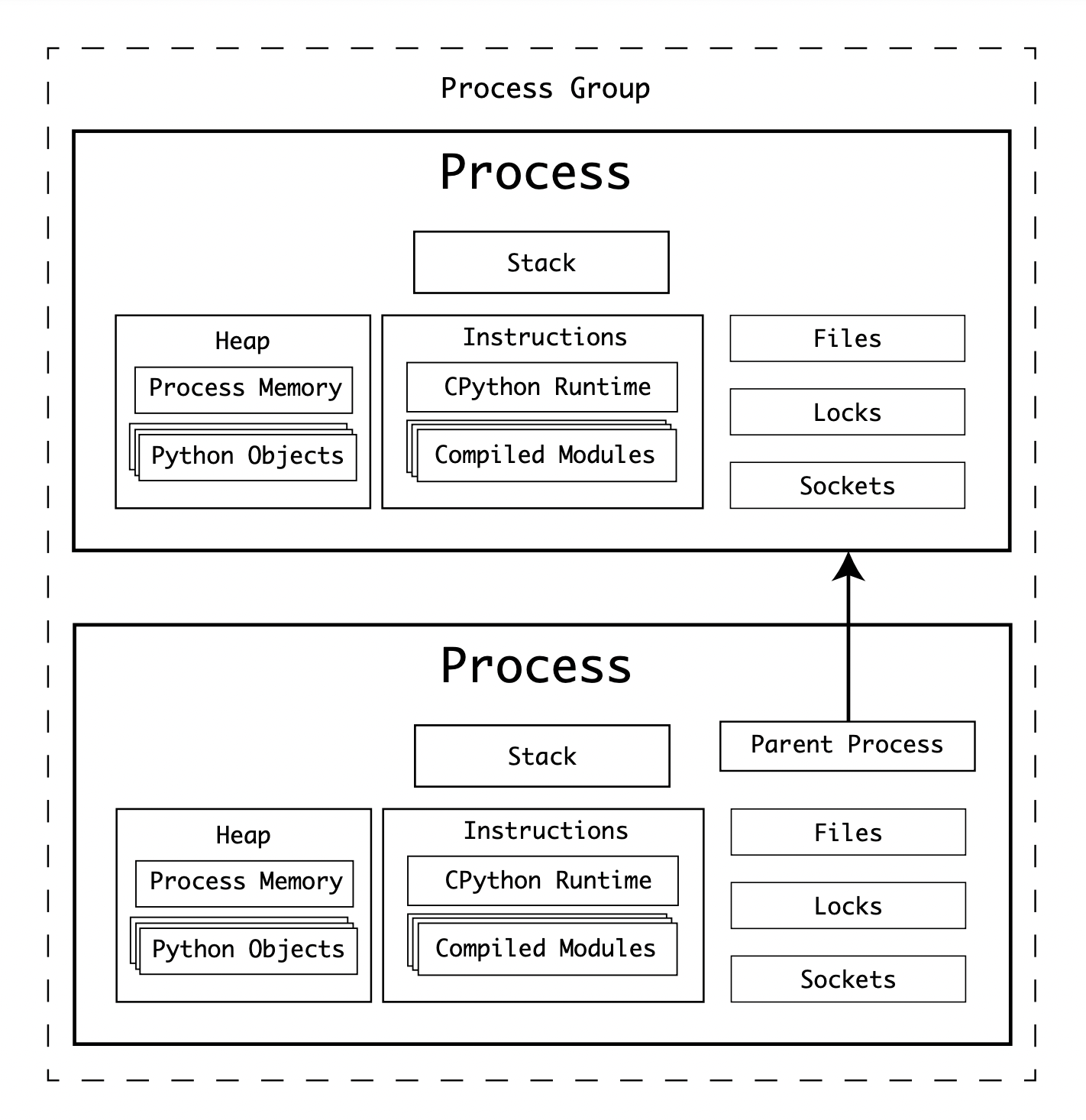
The biggest downside with this approach to parallelism is that the child process is a complete copy of the parent process. In the case of CPython, this means you would have 2 CPython interpreters running, and both would have to load the modules and all the libraries. It creates significant overhead. Using multiple processes makes sense when the overhead of forking a process is outweighed by the size of the task being completed.
Another major downside of forked processes is that they have a separate, isolated, heap from the parent process. This means that the child process cannot write to the memory space of the parent process. When creating the child process, the parent’s heap becomes available to the child process. To send information back to the parent, some form of Inter-Process-Communication (IPC) must be used.
Note
The os module offers a wrapper around the
fork()function.
Multi-Processing in Windows
So far, you’ve been reading the POSIX model. Windows doesn’t provide an equivalent to fork(), and Python should (as best as possible) have the same API across Linux, macOS, and Windows.
To overcome this, the CreateProcessW() API is used to spawn another python.exe process with a -c command-line argument.
This step is known as “spawning,” a process and is also available on POSIX. You’ll see references to it throughout this chapter.
The multiprocessing Package
CPython provides an API on top of the Operating System process forking API. This API makes it simple to create multi-process parallelism in Python. This API is available from the multiprocessing package. This package provides expansive capabilities for pooling processes, queues, forking, creating shared memory heaps, connecting processes together, and more.
Related Source Files
Source files related to multiprocessing are:
| File | Purpose |
|---|---|
Lib/multiprocessing |
Python Source for the multiprocessing package |
Modules/_posixsubprocess.c |
C extension module wrapping the POSIX fork() syscall |
Modules/_winapi.c |
C extension module wrapping the Windows Kernel APIs |
Modules/_multiprocessing |
C extension module used by the multiprocessing package |
PC/msvcrtmodule.c |
A Python interface to the Microsoft Visual C Runtime Library |
Spawning and Forking Processes
The multiprocessing package offers three methods to start a new parallel process.
- Forking an Interpreter (on POSIX only)
- Spawning a new Interpreter process (on POSIX and Windows)
- Running a Fork Server, where a new process is created which then forks any number of processes (on POSIX only)
Note
For Windows and macOS, the default start method is Spawning. For Linux, the default is Forking. You can override the default method using the
multiprocessing.set_start_method()function.
The Python API for starting a new process takes a callable, target, and a tuple of arguments, args. Take this simple example of spawning a new process to convert Fahrenheit to Celcius:
import multiprocessing as mp
import os
def to_celcius(f):
c = (f - 32) * (5/9)
pid = os.getpid()
print(f"{f}F is {c}C (pid {pid})")
if __name__ == '__main__':
mp.set_start_method('spawn')
p = mp.Process(target=to_celcius, args=(110,))
p.start()
While you can start a single process, the multiprocessing API assumes you want to start multiple. There are convenience methods for spawning multiple processes and feeding them sets of data. One of those methods is the Pool class.
The previous example can be expanded to calculate a range of values in separate Python interpreters:
import multiprocessing as mp
import os
def to_celcius(f):
c = (f - 32) * (5/9)
pid = os.getpid()
print(f"{f}F is {c}C (pid {pid})")
if __name__ == '__main__':
mp.set_start_method('spawn')
with mp.Pool(4) as pool:
pool.map(to_celcius, range(110, 150, 10))
Note that the output shows the same PID. Because the CPython interpreter process has a signification overhead, the Pool will consider each process in the pool a “worker.” If a worker has completed, it will be reused. If you replace the line:
with mp.Pool(4) as pool:
with:
with mp.Pool(4, maxtasksperchild=1) as pool:
Thie previous multiprocessing examle will print something similar to:
python pool_process_celcius.py
110F is 43.333333333333336C (pid 5654)
120F is 48.88888888888889C (pid 5653)
130F is 54.44444444444445C (pid 5652)
140F is 60.0C (pid 5655)
The output shows the process IDs of the newly spawned processes and the calculated values.
Creation of Child Processes
Both of these scripts will create a new Python interpreter process and pass data to it using pickle.
Note
The
picklemodule is a serialization package used for serializing Python objects. Davide Mastromatteo has written a great write up of the pickle module at realpython.com.
For POSIX systems, the creation of the subprocess by the multiprocessing module is equivalent to this command:
python -c 'from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=<i>, pipe_handle=<j>)' --multiprocessing-fork
Where i the filehandle descriptor, and j the pipe handle descriptor.
For Windows systems, the parent PID is used instead of a tracker file descriptor:
python.exe -c 'from multiprocessing.spawn import spawn_main; spawn_main(parent_pid=<k>, pipe_handle=<j>)' --multiprocessing-fork
Where k the parent PID and j the pipe handle descriptor.
Piping Data to the Child Process
When the new child process has been instantiated on the OS, it will wait for initialization data from the parent process. The parent process writes 2 objects to a pipe file stream. The pipe file stream is a special IO stream used to send data between processes on the command line.
The first object written by the parent process is the preparation data object. This object is a dictionary containing some information about the parent, such as the executing directory, the start method, any special command-line arguments, and the sys.path. You can see an example of what is generated by running multiprocessing.spawn.get_preparation_data(name):
>>> import multiprocessing.spawn
>>> import pprint
>>> pprint.pprint(multiprocessing.spawn.get_preparation_data("example"))
{
'authkey': b'x90xaa_x22[x18rixbcag]x93xfexf5xe5@[wJx99p#x00'
b'xcexd4)1j.xc3c',
'dir': '/Users/anthonyshaw',
'log_to_stderr': False,
'name': 'example',
'orig_dir': '/Users/anthonyshaw',
'start_method': 'spawn',
'sys_argv': [''],
'sys_path': ['/Users/anthonyshaw']
}
The second object written is the BaseProcess child class instance. Depending on how multiprocessing was called and which Operating System is being used, one of the child classes of BaseProcess will be the instance serialized.
Both the preparation data and process object are serialized using the pickle module and written to the parent process’ pipe stream:
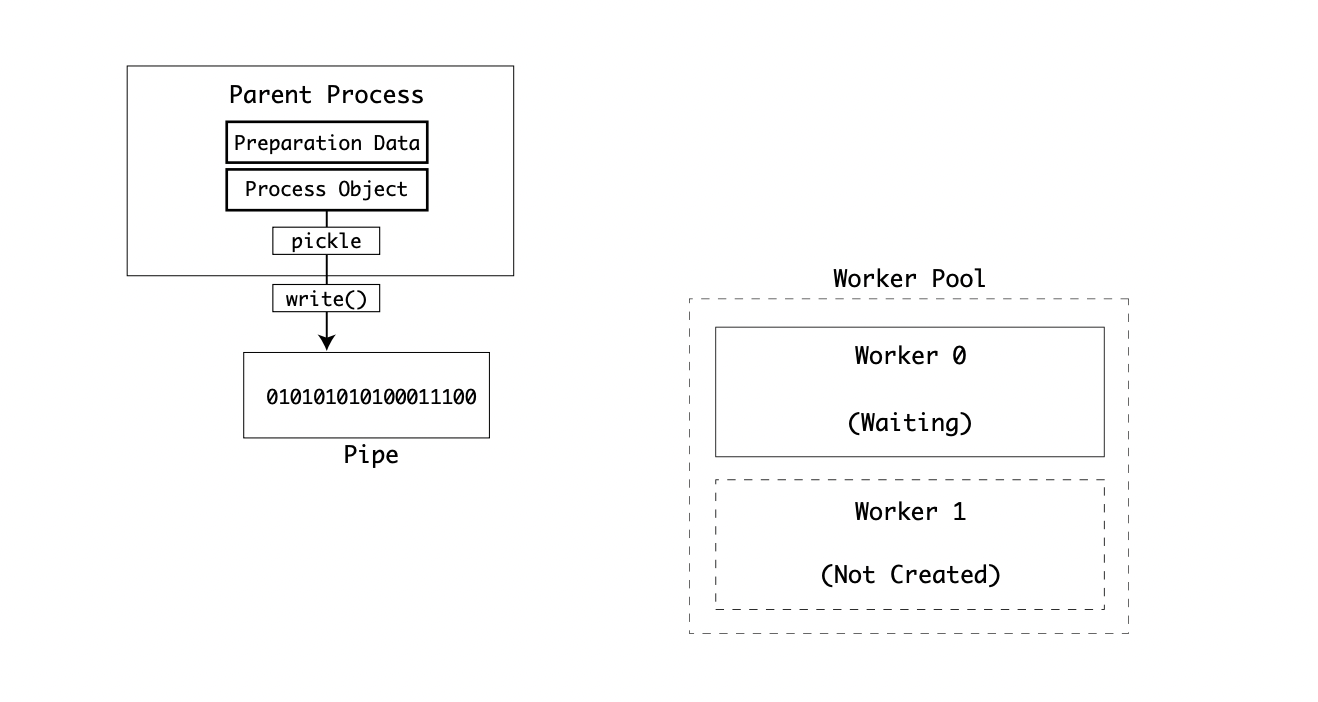
Note
The POSIX implementation of the child process spawning and serialization process is located in
Lib > multiprocessing > popen_spawn_posix.py. The Windows implementation is located inLib > multiprocessing > popen_spawn_win32.py.
Executing the Child Process
The entry point of the child process, multiprocessing.spawn.spawn_main() takes the argument pipe_handle and either parent_pid for Windows or tracked_fd for POSIX:
def spawn_main(pipe_handle, parent_pid=None, tracker_fd=None):
'''
Run code specified by data received over pipe
'''
assert is_forking(sys.argv), "Not forking"
For Windows, the function will call the OpenProcess API of the parent PID. This process object is used to create a filehandle, fd, of the parent process pipe:
if sys.platform == 'win32':
import msvcrt
import _winapi
if parent_pid is not None:
source_process = _winapi.OpenProcess(
_winapi.SYNCHRONIZE | _winapi.PROCESS_DUP_HANDLE,
False, parent_pid)
else:
source_process = None
new_handle = reduction.duplicate(pipe_handle,
source_process=source_process)
fd = msvcrt.open_osfhandle(new_handle, os.O_RDONLY)
parent_sentinel = source_process
For POSIX, the pipe_handle becomes the file descriptor, fd, and is duplicated to become the parent_sentinel value:
else:
from . import resource_tracker
resource_tracker._resource_tracker._fd = tracker_fd
fd = pipe_handle
parent_sentinel = os.dup(pipe_handle)
Next, the _main() function is called with the parent pipe file handle, fd, and the parent process sentinel, parent_sentinel. Whatever the return value of _main() is becomes the exit code for the process and the interpreter is terminated:
exitcode = _main(fd, parent_sentinel)
sys.exit(exitcode)
The _main() function is called with the file descriptor of the parent processes pipe and the parent sentinel for checking if the parent process has exited whilst executing the child.
The main function deserialises the binary data on the fd byte stream. Remember, this is the pipe file handle. The deserialization happens using using same pickle library that the parent process used:
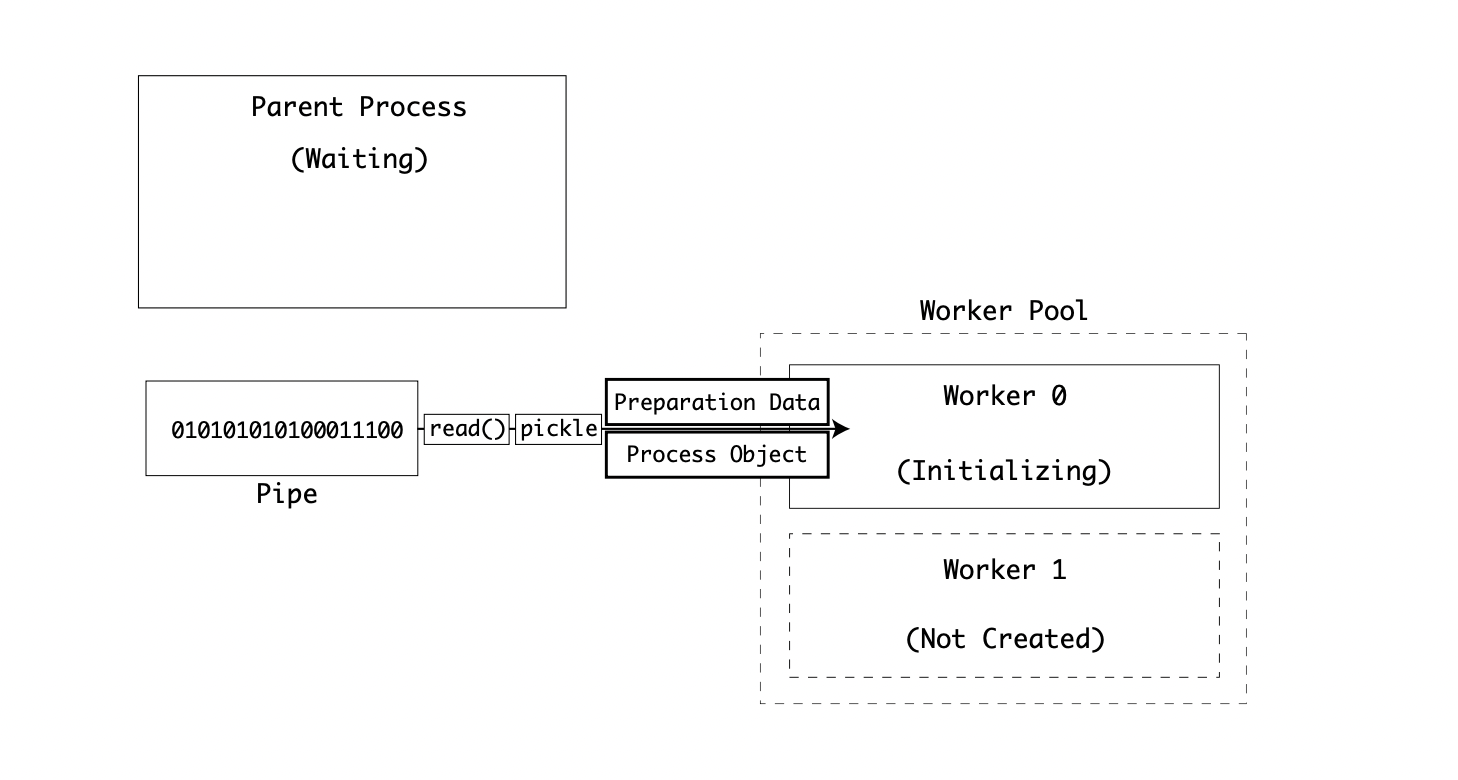
The first value is a dict containing the preparation data. The second value is an instance of SpawnProcess which is then used at the instance to call _bootstrap() upon:
def _main(fd, parent_sentinel):
with os.fdopen(fd, 'rb', closefd=True) as from_parent:
process.current_process()._inheriting = True
try:
preparation_data = reduction.pickle.load(from_parent)
prepare(preparation_data)
self = reduction.pickle.load(from_parent)
finally:
del process.current_process()._inheriting
return self._bootstrap(parent_sentinel)
The _bootstrap() function handles the instantiation of a BaseProcess instance from the deserialized data, and then the target function is called with the arguments and keyword arguments. This final task is completed by BaseProcess.run():
def run(self):
'''
Method to be run in sub-process; can be overridden in sub-class
'''
if self._target:
self._target(*self._args, **self._kwargs)
The exit code of self._bootstrap() is set as the exit code, and the child process is terminated. This process allows the parent process to serialize the module and the executable function. It also allows the child process to deserialize that instance, execute the function with arguments, and return. It does not allow for the exchanging of data once the child process has started. This task is done using the extension of the Queue and Pipe objects. If processes are being created in a pool, the first process will be ready and in a waiting state. The parent process repeats the process and sends the data to the next worker:
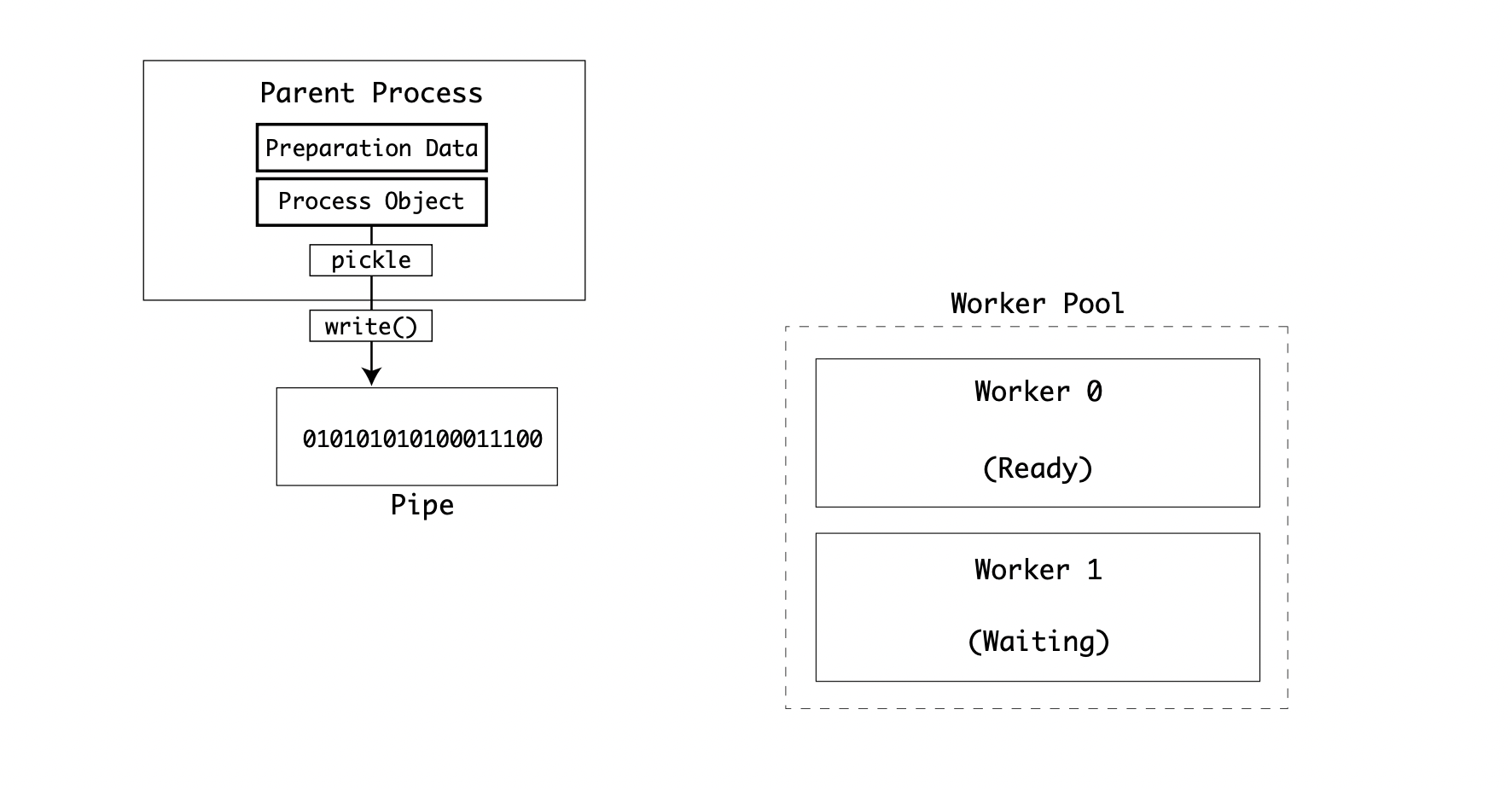
The next worker receives the data and initializes its state and runs the target function:
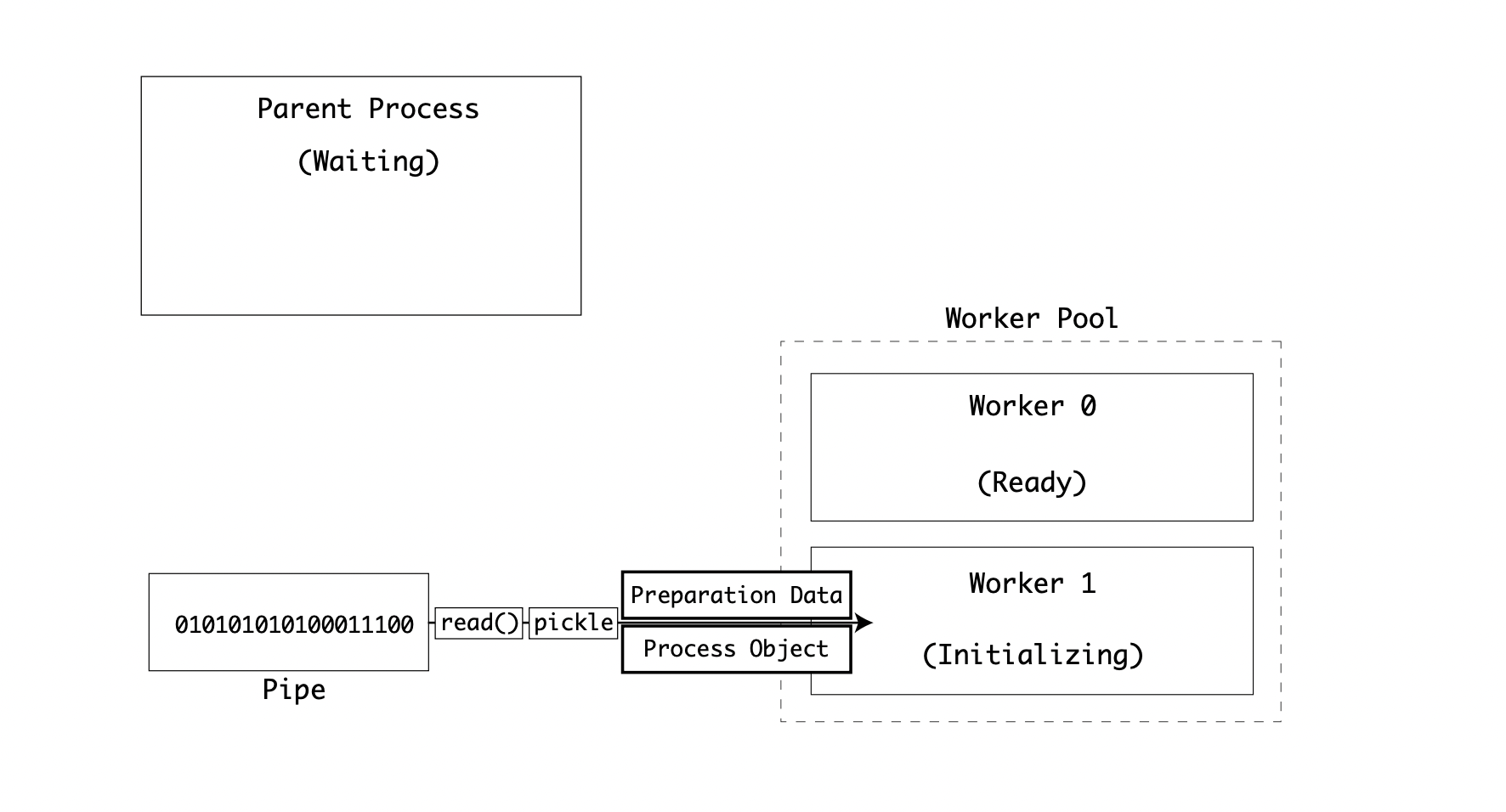
To share any data beyond initialization, queues and pipes must be used.
Exchanging Data with Queues and Pipes
In the previous section you saw how child processes are spawned, and then the pipe is used as a serialization stream to tell the child process what function to call with arguments. There is two types of communication between processes, depending on the nature of the task.
Semaphores
Many of the mechanisms in multiprocessing use semaphores as a way of signaling that resources are locked, being waited on, or not used. Operating Systems use binary semaphores as a simple variable type for locking resources, like files, sockets, and other resources.
If one process is writing to a file or a network socket, you don’t want another process to suddenly start writing to the same file. The data would become corrupt instantly. Instead, Operating Systems put a “lock” on resources using a semaphore. Processes can also signal that they are waiting for that lock to be released so that when it is, they get a message to say it is ready and they can start using it.
Semaphores (in the real world) are a signaling method using flags, so the states for a resource of waiting, locked and not-used would look like:
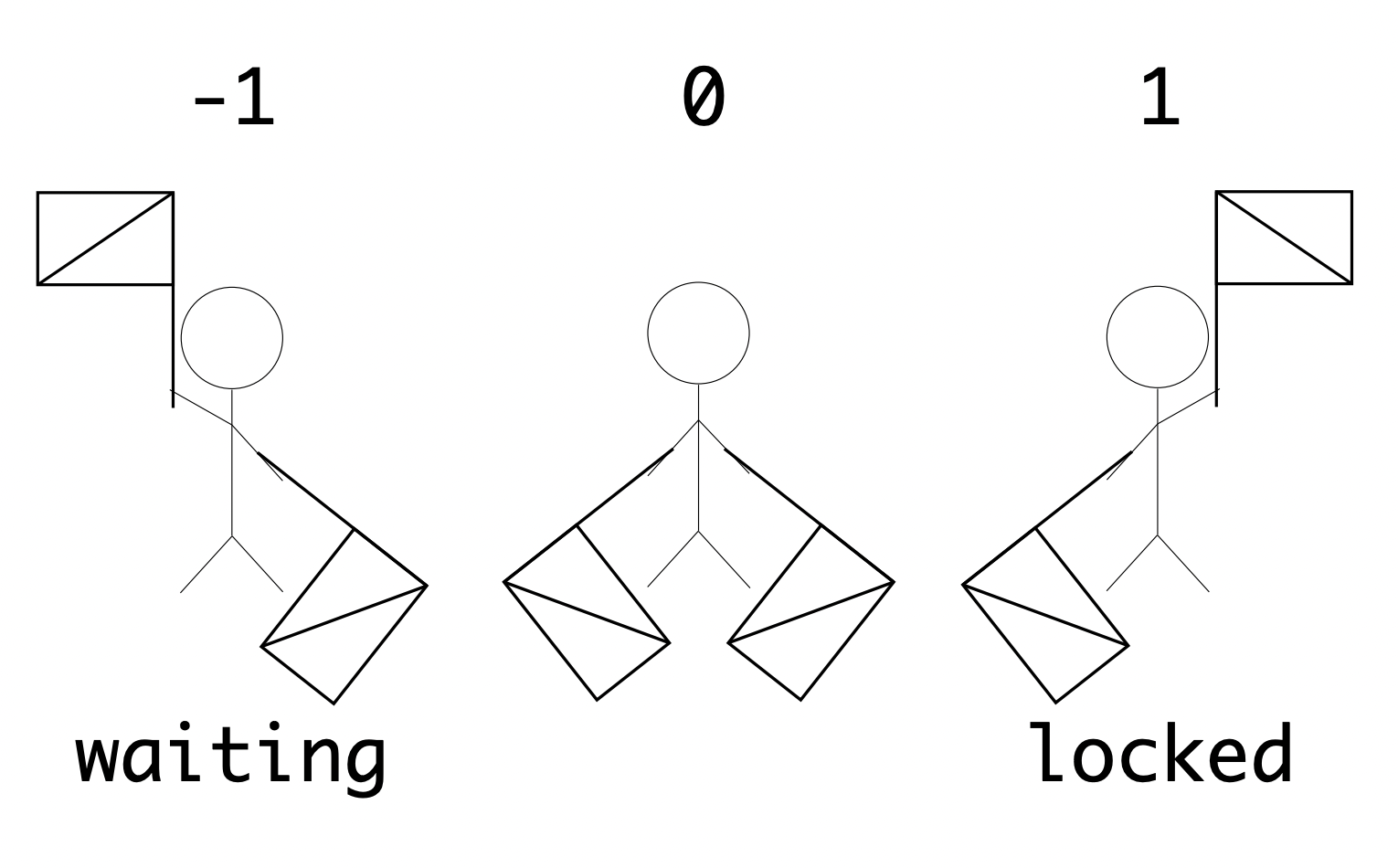
The semaphore API is different between Operating Systems, so there is an abstraction class, multiprocessing.syncronize.Semaphore.
Semaphores are used by CPython for multiprocessing because they are both thread-safe and process-safe. The Operating System handles any potential deadlocks of reading or writing to the same semaphore.
The implementation of these semaphore API functions is located in a C extension module Modules/_multiprocessing/semaphore.c. This extension module offers a single method for creating, locking, releasing semaphores, and other operations.
The call to the Operating System is through a series of Macros, which are compiled into different implementations depending on the Operating System platform. For Windows, the winbase.h API functions for semaphores are used:
#define SEM_CREATE(name, val, max) CreateSemaphore(NULL, val, max, NULL)
#define SEM_CLOSE(sem) (CloseHandle(sem) ? 0 : -1)
#define SEM_GETVALUE(sem, pval) _GetSemaphoreValue(sem, pval)
#define SEM_UNLINK(name) 0
For POSIX, the macros use the semaphore.h API is used:
#define SEM_CREATE(name, val, max) sem_open(name, O_CREAT | O_EXCL, 0600, val)
#define SEM_CLOSE(sem) sem_close(sem)
#define SEM_GETVALUE(sem, pval) sem_getvalue(sem, pval)
#define SEM_UNLINK(name) sem_unlink(name)
Queues
Queues are a great way of sending small data to and from multiple processes.
If you adapt the multiprocessing example before to use a multiprocessing Manager() instance, and create two queues:
inputsto hold the input Fahrenheit valuesoutputsto hold the resulting Celcius values Change the pool size to 2 so that there are two workers:
import multiprocessing as mp
def to_celcius(input: mp.Queue, output: mp.Queue):
f = input.get()
# time-consuming task ...
c = (f - 32) * (5/9)
output.put(c)
if __name__ == '__main__':
mp.set_start_method('spawn')
pool_manager = mp.Manager()
with mp.Pool(2) as pool:
inputs = pool_manager.Queue()
outputs = pool_manager.Queue()
input_values = list(range(110, 150, 10))
for i in input_values:
inputs.put(i)
pool.apply(to_celcius, (inputs, outputs))
for f in input_values:
print(outputs.get(block=False))
This would print the list of tuples returned to the results queue:
python pool_queue_celcius.py
43.333333333333336
48.88888888888889
54.44444444444445
60.0
The parent process first puts the input values onto the input queue. The first worker then takes an item from the queue. Each time an item is taken from the queue using .get(), a semaphore lock is used on the queue object:
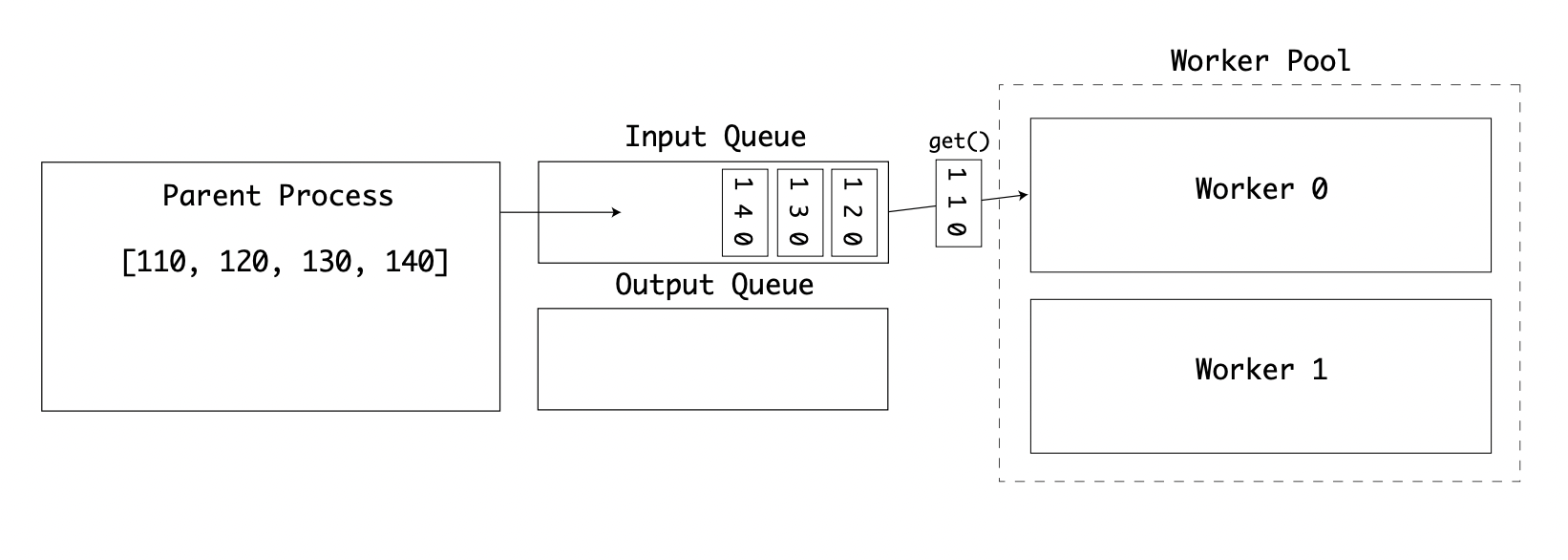
While this worker is busy, the second worker then takes another value from the queue:
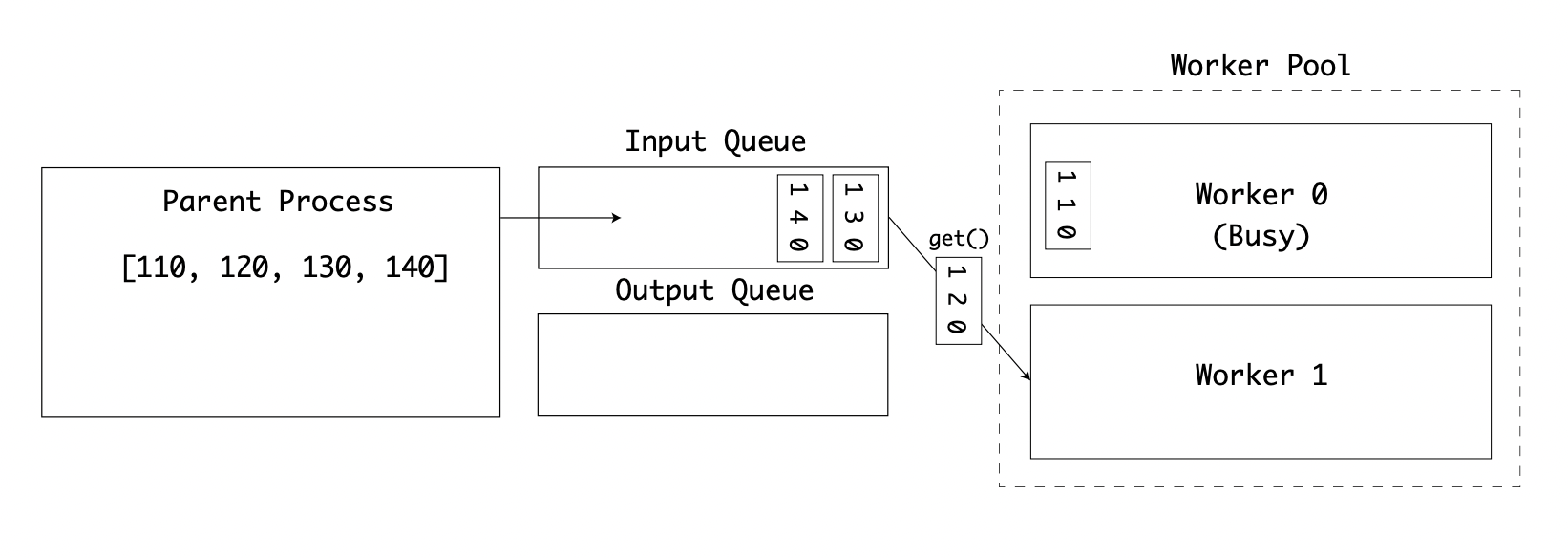
The first worker has completed its calculation and puts the resulting value onto the result queue:
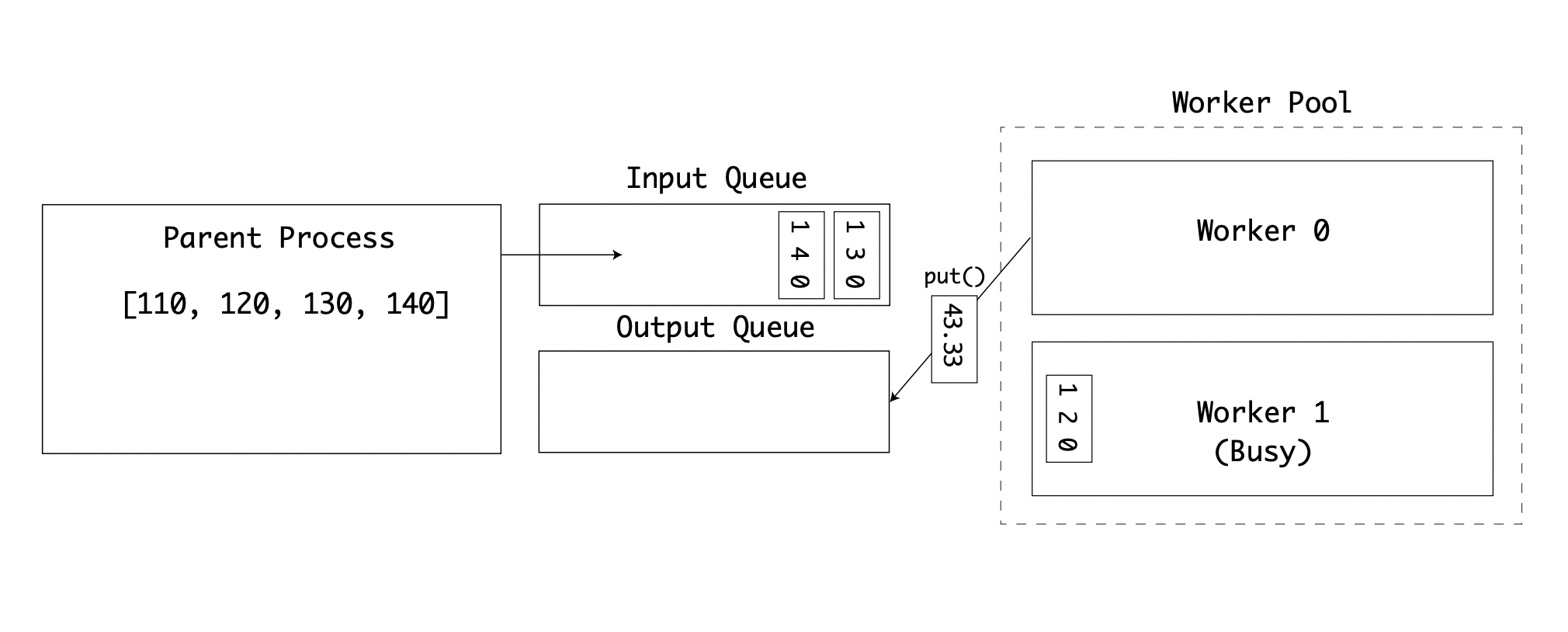
Two queues are in use to separate the input and output values. Eventually, all input values have been processed, and the output queue is full. The values are then printed by the parent process:
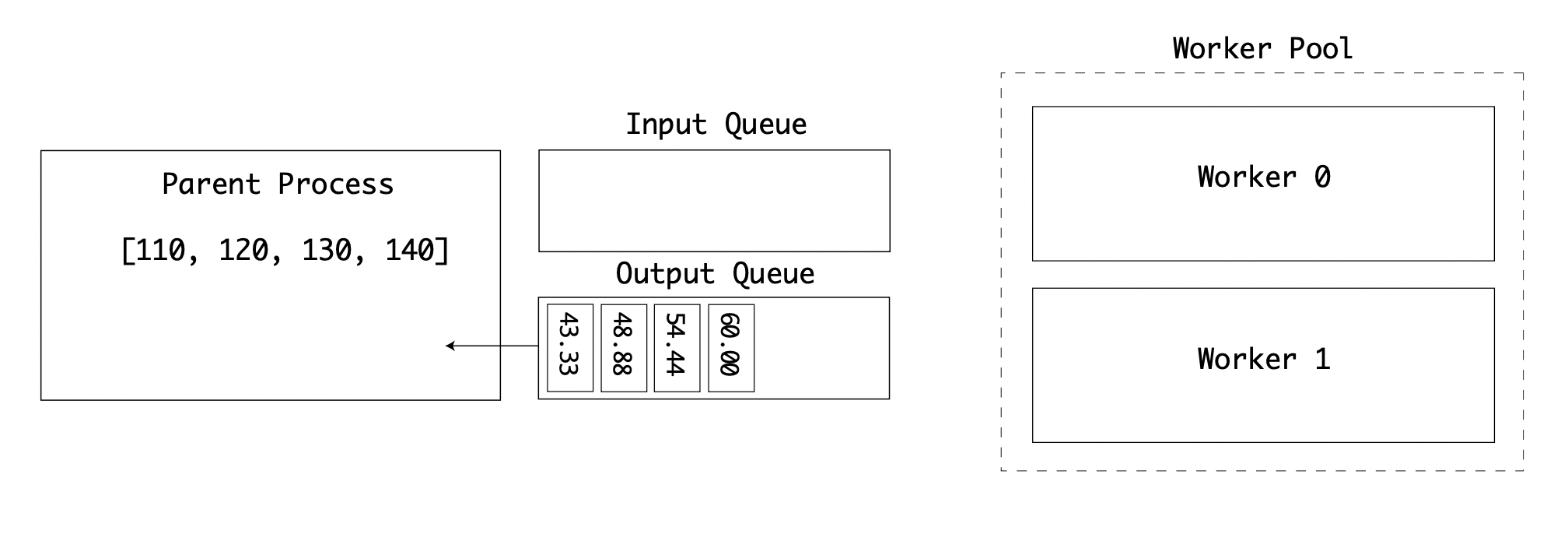
This example shows how a pool of workers could receive a queue of small, discreet values and process them in parallel to send the resulting data back to the host process. In practice, converting Celcius to Fahrenheit is a small, trivial calculation unsuited for parallel execution. If the worker process were doing another CPU-intensive calculation, this would provide significant performance improvement on a multi-CPU or multi-core computer.
For streaming data instead of discreet queues, pipes can be used instead.
Pipes
Within the multiprocessing package, there is a type Pipe. Instantiating a Pipe returns two connections, a parent and a child. Both can send and receive data:
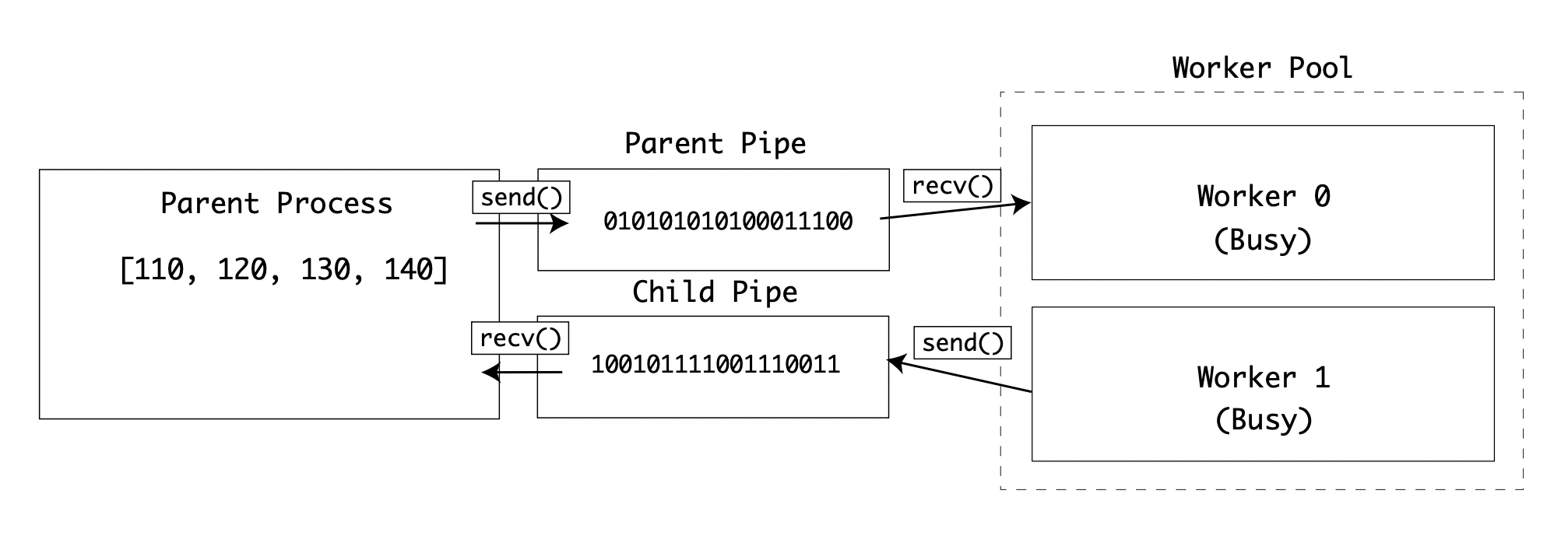
In the queue example, a lock is implicitly placed on the queue when data is sent and received. Pipes do not have that behavior, so you have to be careful that two processes do not try and write to the same pipe at the same time.
If you adapt the last example to work with a pipe, it will require changing the pool.apply() to pool.apply_async(). This changes the execution of the next process to a non-blocking operation:
import multiprocessing as mp
def to_celcius(child_pipe: mp.Pipe, parent_pipe: mp.Pipe):
f = parent_pipe.recv()
# time-consuming task ...
c = (f - 32) * (5/9)
child_pipe.send(c)
if __name__ == '__main__':
mp.set_start_method('spawn')
pool_manager = mp.Manager()
with mp.Pool(2) as pool:
parent_pipe, child_pipe = mp.Pipe()
results = []
for i in range(110, 150, 10):
parent_pipe.send(i)
pool.apply_async(to_celcius, args=(child_pipe, parent_pipe))
print(child_pipe.recv())
parent_pipe.close()
child_pipe.close()
In this example, there is a risk of two or more processes trying to read from the parent pipe at the same time on the line:
f = parent_pipe.recv()
There is also a risk of two or more processes trying to write to the child pipe at the same time.
child_pipe.send(c)
If this situation occurs, data would be corrupted in either the receive or send operations:
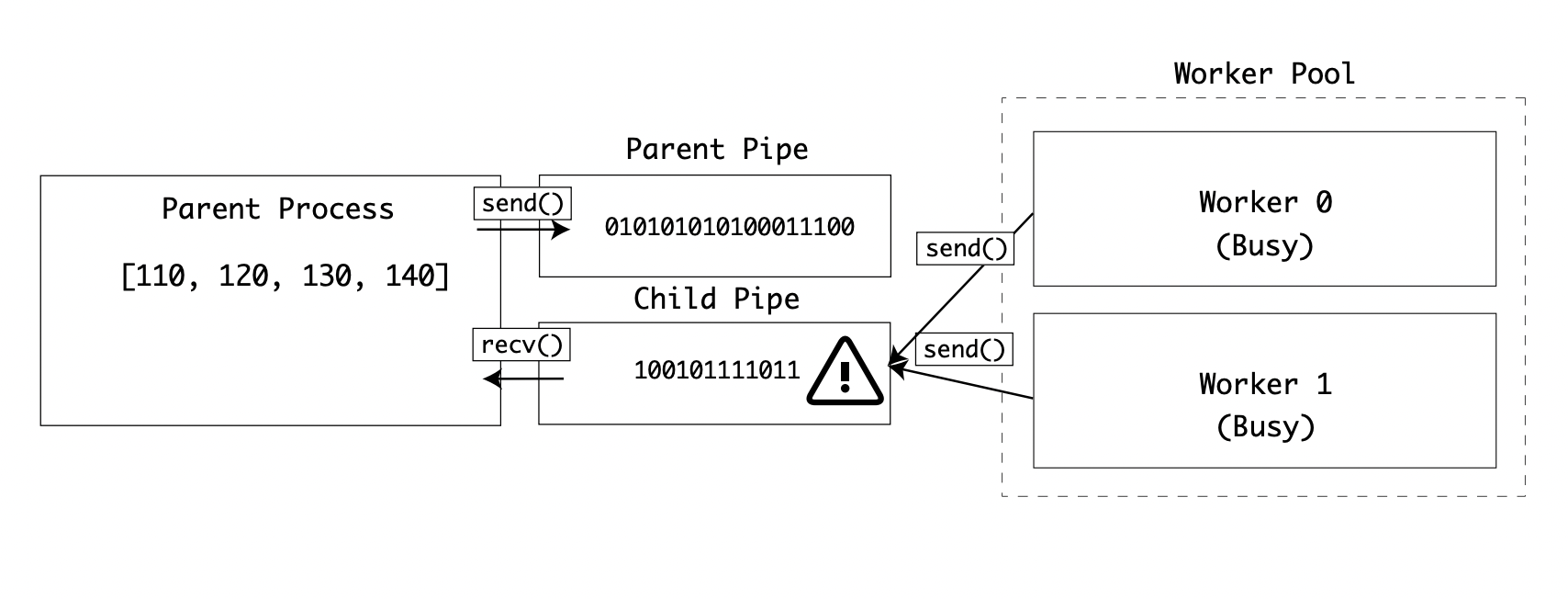
To avoid this, you can implement a semaphore lock on the Operating System. Then all child processes will check with the Lock before reading or writing to the same pipe.
There are two locks required, one on the receiving end of the parent pipe, and another on the sending end of the child pipe:
import multiprocessing as mp
def to_celcius(child_pipe: mp.Pipe, parent_pipe: mp.Pipe,
child_write_lock: mp.Lock, parent_read_lock: mp.Lock):
parent_read_lock.acquire()
try:
f = parent_pipe.recv()
finally:
parent_read_lock.release()
# time-consuming task ...
c = (f - 32) * (5/9)
child_write_lock.acquire()
try:
child_pipe.send(c)
finally:
child_write_lock.release()
if __name__ == '__main__':
mp.set_start_method('spawn')
pool_manager = mp.Manager()
with mp.Pool(2) as pool:
parent_pipe, child_pipe = mp.Pipe()
parent_read_lock = mp.Lock()
child_write_lock = mp.Lock()
results = []
for i in range(110, 150, 10):
parent_pipe.send(i)
pool.apply_async(to_celcius, args=(child_pipe, parent_pipe,
child_write_lock,
parent_read_lock))
print(child_pipe.recv())
parent_pipe.close()
child_pipe.close()
Now the worker processes will wait to acquire a lock before receiving data, and wait again to acquire another lock to send data:
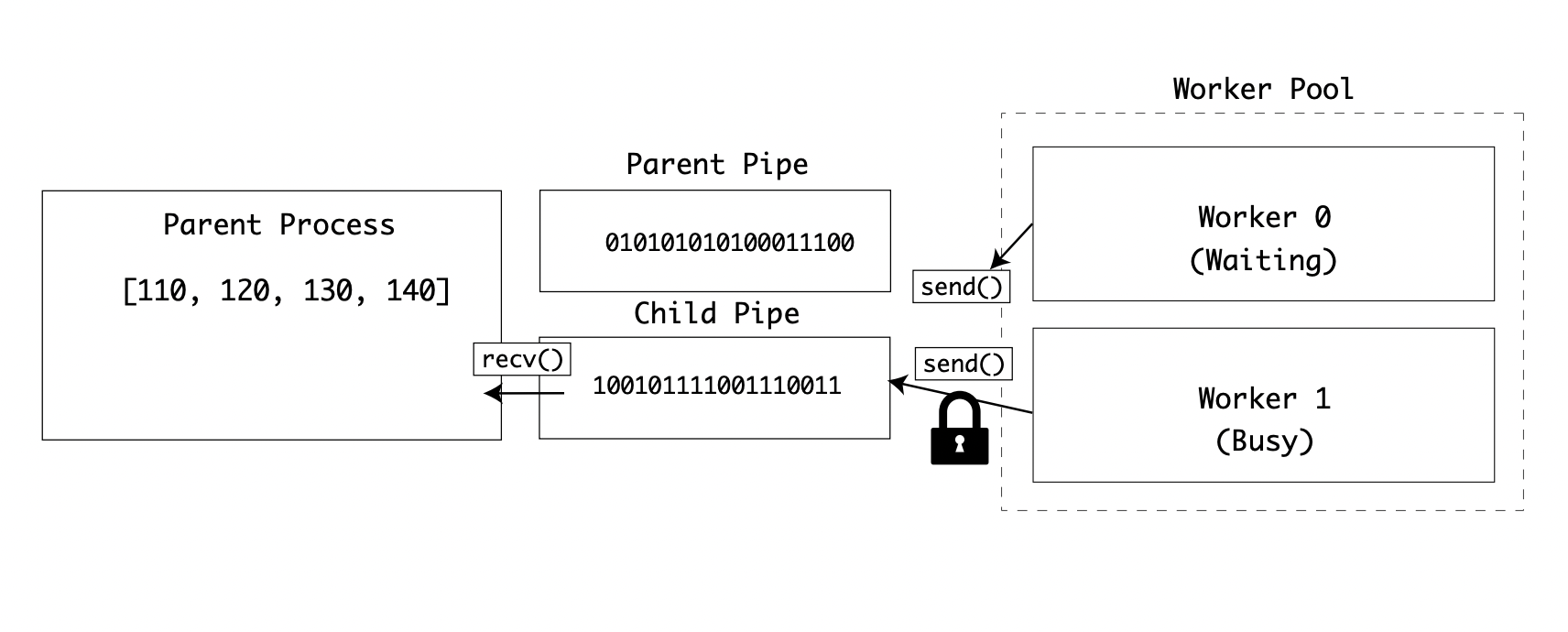
This example would suit situations where the data going over the pipe is large because the chance of a collision is higher.
Shared State Between Processes
So far, you have seen how data can be shared between the child and the parent process. There may be scenarios where you want to share data between child processes. In this situation, the multiprocessing package provides two solutions:
- A performant Shared Memory API using shared memory maps and shared C types
- A flexible Server Process API supporting complex types via the Manager class
Example Application
As a demonstration application, throughout this chapter, you will be refactoring a TCP port scanner for different concurrency and parallelism techniques.
Over a network, a host can be contacted on ports, which are a number from 1-65535. Common services have standard ports. For example, HTTP operates on port 80 and HTTPS on 443. TCP port scanners are used as a common network testing tool to check that packets can be sent over a network.
This code example uses the Queue interface, a thread-safe queue implementation similar to the one you use in the multiprocessing examples. The code also uses the socket package to try connecting to a remote port with a short timeout of 1 second.
The check_port() function will see if the host responds on the given port, and if it does respond, it adds the port number to the results queue.
When the script is executed, the check_port() function is called in sequence for port numbers 80-100.
After this has completed, the results queue is emptied out, and the results are printed on the command line.
So you can compare the difference, it will print the execution time at the end:
from queue import Queue
import socket
import time
timeout = 1.0
def check_port(host: str, port: int, results: Queue):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
if result == 0:
results.put(port)
sock.close()
if __name__ == '__main__':
start = time.time()
host = "localhost" # replace with a host you own
results = Queue()
for port in range(80, 100):
check_port(host, port, results)
while not results.empty():
print("Port {0} is open".format(results.get()))
print("Completed scan in {0} seconds".format(time.time() - start))
The execution will print out the open ports and the time taken:
python portscanner.py
Port 80 is open
Completed scan in 19.623435020446777 seconds
This example can be refactored to use multiprocessing. The Queue interface is swapped for multiprocessing.Queue and the ports are scanned together using a pool executor:
import multiprocessing as mp
import time
import socket
timeout = 1
def check_port(host: str, port: int, results: mp.Queue):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
if result == 0:
results.put(port)
sock.close()
if __name__ == '__main__':
start = time.time()
processes = []
scan_range = range(80, 100)
host = "localhost" # replace with a host you own
mp.set_start_method('spawn')
pool_manager = mp.Manager()
with mp.Pool(len(scan_range)) as pool:
outputs = pool_manager.Queue()
for port in scan_range:
processes.append(pool.apply_async(check_port,
(host, port, outputs)))
for process in processes:
process.get()
while not outputs.empty():
print("Port {0} is open".format(outputs.get()))
print("Completed scan in {0} seconds".format(time.time() - start))
As you might expect, this application is much faster because it is testing each port in parallel:
python portscanner_mp_queue.py
Port 80 is open
Completed scan in 1.556523084640503 seconds
Conclusion
Multiprocessing offers a scalable, parallel execution API for Python. Data can be shared between processes, and CPU-intensive work can be broken into parallel tasks to take advantage of multiple core or CPU computers.
Multiprocessing is not a suitable solution when the task to be completed is not CPU intensive, but instead IO-bound. For example, if you spawned 4 worker processes to read and write to the same files, one would do all the work, and the other 3 would wait for the lock to be released.
Multiprocessing is also not suitable for short-lived tasks, because of the time and processing overhead of starting a new Python interpreter.
In both of those scenarios, you main find one of the next approaches is more suited.
Multithreading
CPython provides a high-level and a low-level API for creating, spawning, and controlling threads from Python. To understand Python threads, you should first understand how Operating System threads work. There are two implementations of threading in CPython.
pthreads- POSIX threads for Linux and macOSnt threads- NT threads for Windows
In the section on The Structure of a Process, you saw how a process has:
- A Stack of subroutines
- A Heap of memory
- Access to Files, Locks, and Sockets on the Operating System
The biggest limitation to scaling a single process is that the Operating System will have a single Program Counter for that executable.
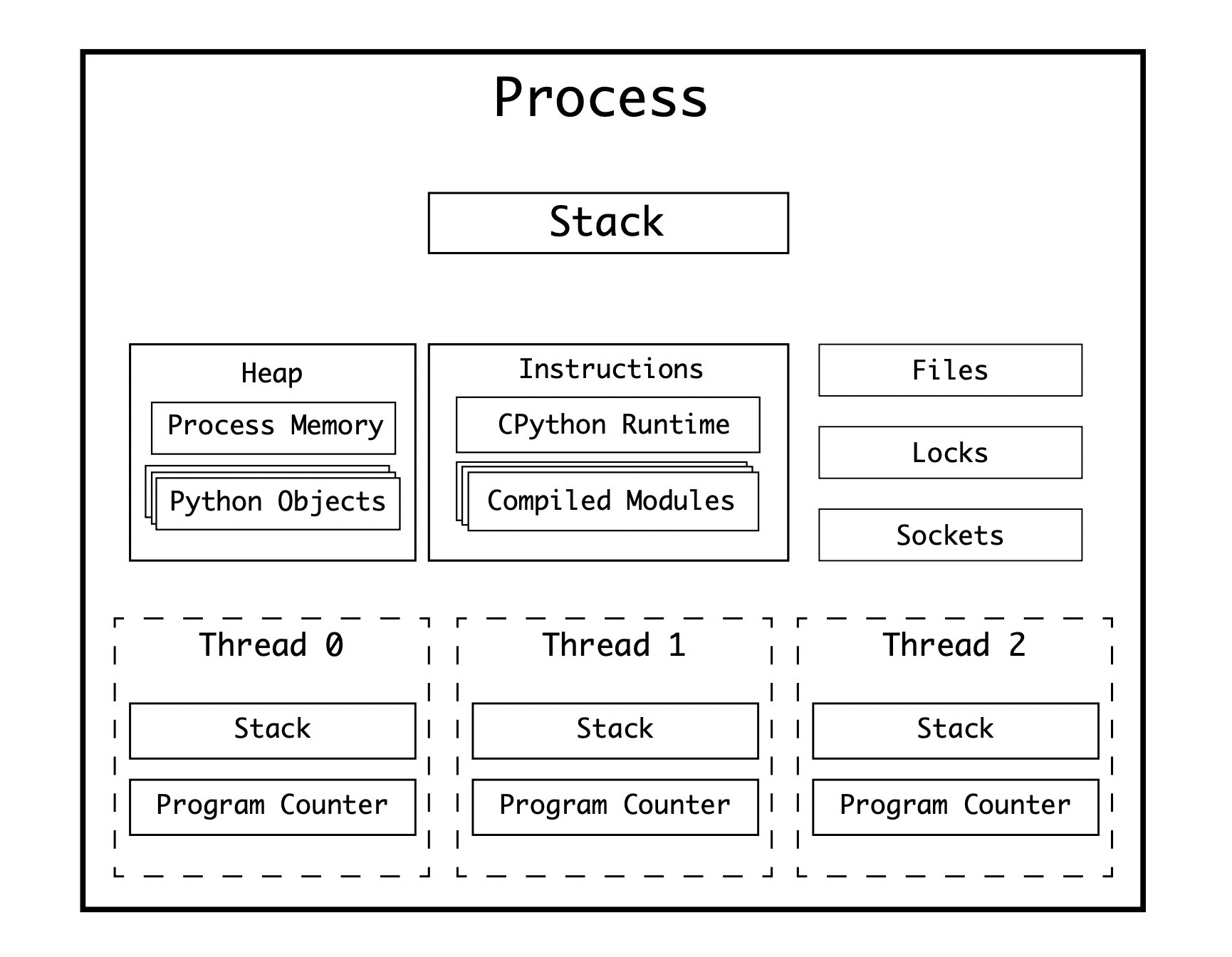
To get around this, modern Operating Systems allow processes to signal the Operating System to branch their execution into multiple threads.
Each thread will have its own Program Counter, but use the same resources as the host process. Each thread also has it’s own call stack, so it can be executing a different function.
Because multiple threads can read and write to the same memory space, collisions could occur. The solution to this is thread safety and involves making sure that memory space is locked by a single thread before it is accessed.
A single process with 3 threads would have a structure:
Note
For a great introductory tutorial on the Python threading API, check out Jim Anderson’s “Intro to Python Threading.”
The GIL
If you’re familiar with NT threads or POSIX threads from C, or you’ve used another high-level language, you may expect multithreading to be parallel.
In CPython, the threads are based on the C APIs, but the threads are Python threads. This means that every Python thread needs to execute Python bytecode through the evaluation loop.
The Python evaluation loop is not thread-safe. There are many parts of the interpreter state, such as the Garbage Collector, which are shared, and global.
To get around this, the CPython developers implemented a mega-lock, called the Global Interpreter Lock (GIL). Before any opcode is executed in the frame-evaluation loop, the GIL is acquired by the thread, then once the opcode has been executed, it is released.
Aside from providing a global thread-safety to every operation in Python, this approach has a major drawback. Any operations which take a long time to execute will leave other threads waiting for the GIL to be released before they can execute.
This means that only 1 thread can be executing a Python bytecode operation at any one time.
To acquire the GIL, a call is made to take_gil() and then again to drop_gil() to release it. The GIL acquisition is made within the core frame evaluation loop, _PyEval_EvalFrameDefault().
To stop a single frame execution from permanently holding the GIL, the evaluation loop state stores a flag, gil_drop_request. After every bytecode operation has completed in a frame, this flag is checked, and the GIL is temporarily released and then reacquired:
...
if (_Py_atomic_load_relaxed(&ceval->gil_drop_request)) {
/* Give another thread a chance */
if (_PyThreadState_Swap(&runtime->gilstate, NULL) != tstate) {
Py_FatalError("ceval: tstate mix-up");
}
drop_gil(ceval, tstate);
/* Other threads may run now */
take_gil(ceval, tstate);
/* Check if we should make a quick exit. */
exit_thread_if_finalizing(tstate);
if (_PyThreadState_Swap(&runtime->gilstate, tstate) != NULL) {
Py_FatalError("ceval: orphan tstate");
}
}
...
Despite the limitations that the GIL enforces on parallel execution, it means that multithreading in Python is very safe and ideal for running IO-bound tasks concurrently.
Related Source Files
Source files related to threading are:
| File | Purpose |
|---|---|
Include/pythread.h |
PyThread API and definition |
Lib/threading.py |
High Level threading API and Standard Library module |
Modules/_threadmodule.c |
Low Level thread API and Standard Library module |
Python/thread.c |
C extension for the thread module |
Python/thread_nt.h |
Windows Threading API |
Python/thread_pthread.h |
POSIX Threading API |
Python/ceval_gil.h |
GIL lock implementation |
Starting Threads in Python
To demonstrate the performance gains of having multithreaded code (in spite of the GIL), you can implement a simple network port scanner in Python.
Now clone the previous script but change the logic to spawn a thread for each port using threading.Thread(). This is similar to the multiprocessing API, where it takes a callable, target, and a tuple, args. Start the threads inside the loop, but don’t wait for them to complete. Instead, append the thread instance to a list, threads:
for port in range(800, 100):
t = Thread(target=check_port, args=(host, port, results))
t.start()
threads.append(t)
Once all threads have been created, iterate through the thread list and call .join() to wait for them to complete:
for t in threads:
t.join()
Next, exhaust all the items in the results queue and print them to the screen:
while not results.empty():
print("Port {0} is open".format(results.get()))
The whole script is:
from threading import Thread
from queue import Queue
import socket
import time
timeout = 1.0
def check_port(host: str, port: int, results: Queue):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
if result == 0:
results.put(port)
sock.close()
def main():
start = time.time()
host = "localhost" # replace with a host you own
threads = []
results = Queue()
for port in range(80, 100):
t = Thread(target=check_port, args=(host, port, results))
t.start()
threads.append(t)
for t in threads:
t.join()
while not results.empty():
print("Port {0} is open".format(results.get()))
print("Completed scan in {0} seconds".format(time.time() - start))
if __name__ == '__main__':
main()
When you call this threaded script at the command-line, it will execute 10+ times faster than the single-threaded example:
python portscanner_threads.py
Port 80 is open
Completed scan in 1.0101029872894287 seconds
This also runs 50-60% faster than the multiprocessing example. Remember that multiprocessing has an overhead for starting the new processes, threading does have an overhead, but it is much smaller.
You may be wondering- if the GIL means that only a single operation can execute at once, why is this faster?
The statement that takes 1-1000ms is:
result = sock.connect_ex((host, port))
In the C extension module, Modules/socketmodule.c, the function that implements the connection is:
Modules/socketmodule.c line 3246
static int
internal_connect(PySocketSockObject *s, struct sockaddr *addr, int addrlen, int raise)
{
int res, err, wait_connect;
Py_BEGIN_ALLOW_THREADS
res = connect(s->sock_fd, addr, addrlen);
Py_END_ALLOW_THREADS
Surrounding the system connect() call are the Py_BEGIN_ALLOW_THREADS and Py_END_ALLOW_THREADS macros.
These macros are defined in Include/ceval.h as:
#define Py_BEGIN_ALLOW_THREADS {
PyThreadState *_save;
_save = PyEval_SaveThread();
#define Py_BLOCK_THREADS PyEval_RestoreThread(_save);
#define Py_UNBLOCK_THREADS _save = PyEval_SaveThread();
#define Py_END_ALLOW_THREADS PyEval_RestoreThread(_save);
}
So, when Py_BEGIN_ALLOW_THREADS is called, it calls PyEval_SaveThread(). This function changes the thread state to NULL and drops the GIL:
Python/ceval.c line 480
PyThreadState *PyEval_SaveThread(void)
{
PyThreadState *tstate = PyThreadState_Swap(NULL);
if (tstate == NULL)
Py_FatalError("PyEval_SaveThread: NULL tstate");
assert(gil_created());
drop_gil(tstate);
return tstate;
}
Because the GIL is dropped, it means any other executing thread can continue. This thread will sit and wait for the system call without blocking the evaluation loop.
Once the connect() function has succeeded or timed out, the Py_END_ALLOW_THREADS runs the PyEval_RestoreThread() function with the original thread state.
The thread state is recovered and the GIL is retaken. The call to take_gil() is a blocking call, waiting on a semaphore:
Python/ceval.c line 503
void
PyEval_RestoreThread(PyThreadState *tstate)
{
if (tstate == NULL)
Py_FatalError("PyEval_RestoreThread: NULL tstate");
assert(gil_created());
int err = errno;
take_gil(tstate);
/* _Py_Finalizing is protected by the GIL */
if (_Py_IsFinalizing() && !_Py_CURRENTLY_FINALIZING(tstate)) {
drop_gil(tstate);
PyThread_exit_thread();
Py_UNREACHABLE();
}
errno = err;
PyThreadState_Swap(tstate);
}
This is not the only system call wrapped by the non-GIL-blocking pair Py_BEGIN_ALLOW_THREADS and Py_END_ALLOW_THREADS. There are over 300 uses of it in the Standard Library. Including:
- Making HTTP requests
- Interacting with local hardware
- Encryption
- Reading and writing files
Thread State
CPython provides its own implementation of thread management. Because threads need to execute Python bytecode in the evaluation loop, running a thread in CPython isn’t as simple as spawning an OS thread. Python threads are called PyThread, and you covered them briefly on the CPython Evaluation Loop chapter.
Python threads execute code objects and are spawned by the interpreter.
To recap:
- CPython has a single runtime, which has its own runtime state
- CPython can have one or many interpreters
- An interpreter has a state, called the interpreter state
- An interpreter will take a code object and convert it into a series of frame objects
- An interpreter has at least one thread, each thread has a thread state
- Frame Objects are executed in a stack, called the frame stack
- CPython references variables in a value stack
- The interpreter state includes a linked-list of its threads
A single-threaded, single-interpreter runtime would have the states:
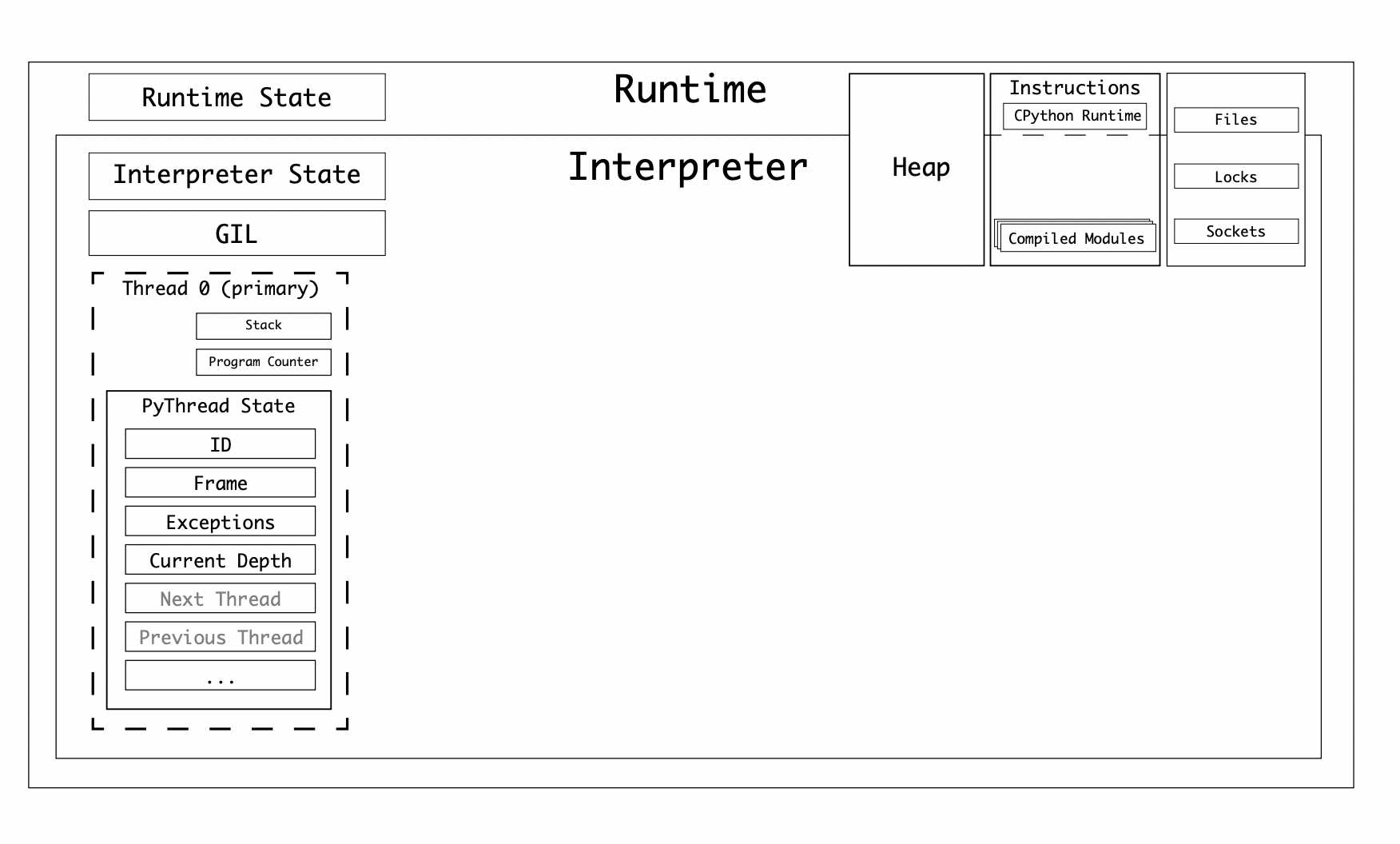
The thread state type, PyThreadState has over 30 properties, including:
- A unique identifier
- A linked-list to the other thread states
- The interpreter state it was spawned by
- The currently executing frame
- The current recursion depth
- Optional tracing functions
- The exception currently being handled
- Any async exception currently being handled
- A stack of exceptions raised
- A GIL counter
- Async generator counters
Similar to the multiprocessing preparation data, threads have a boot state. However, threads share the same memory space, so there is no need to serialize data and send it over a file stream.
Threads are instantiated with the threading.Thread type. This is a highlevel module that abstracts the PyThread type. PyThread instances are managed by the C extension module _thread.
The _thread module has the entry point for executing a new thread, thread_PyThread_start_new_thread(). start_new_thread() is a method on an instance of the type Thread.
New threads are instantiated in this sequence:
- The
bootstateis created, linking to thetarget, with argumentsargsandkwargs - The
bootstateis linked to the interpreter state - A new
PyThreadStateis created, linking to the current interpreter - The GIL is enabled, if not already with a call to
PyEval_InitThreads() - The new thread is started on the Operating System-specific implementation of
PyThread_start_new_thread
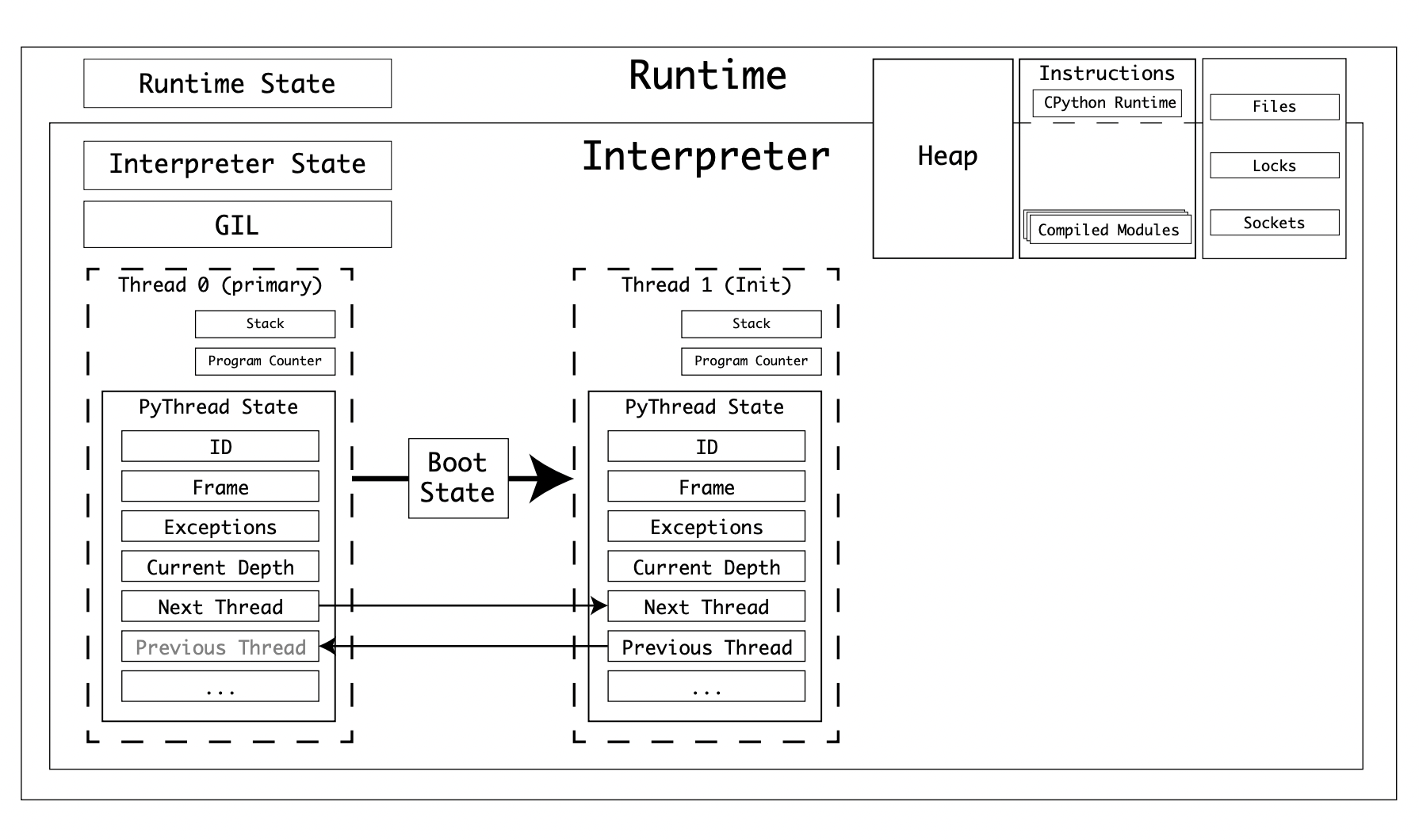
Thread bootstate has the properties:
| Field | Type | Purpose |
|---|---|---|
interp |
PyInterpreterState* |
Link to the interpreter managing this thread |
func |
PyObject * |
Link to the callable to execute upon running the thread |
args |
PyObject *(tuple) |
Arguments to call func with |
key |
PyObject * (dict) |
Keyword arguments to call func with |
tstate |
PyThreadState * |
Thread state for the new thread |
With the thread bootstate, there are two implementations PyThread - POSIX threads for Linux and macOS, and NT threads for Windows.
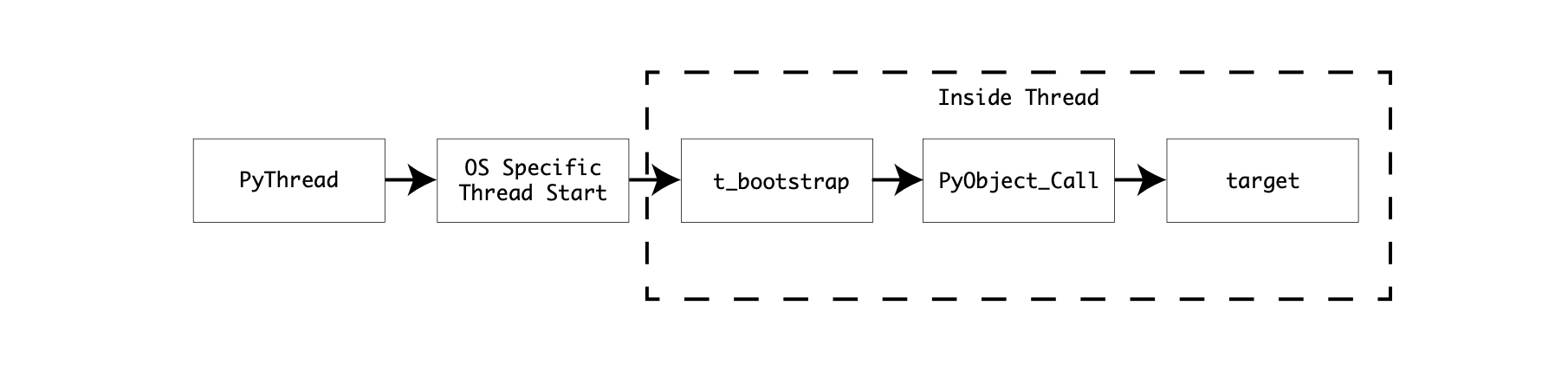
Both of these implementations create the Operating System thread, set it’s attribute and then execute the callback t_bootstrap() from within the new thread. This function is called with the single argument boot_raw, assigned to the bootstate constructed in thread_PyThread_start_new_thread().
The t_bootstrap() function is the interface between a low-level thread and the Python runtime. The bootstrap will initiatilize the thread, then execute the target callable using PyObject_Call(). Once the callable target has been executed, the thread will exit:
POSIX Threads
POSIX threads, named pthreads, have an implementation in Python/thread_pthread.h. This implementation abstracts the pthread.h C API with some additional safeguards and optimizations.
Threads can have a configured stack size. Python has it’s own stack frame construct, as you explored in the chapter on the Evaluation Loop. If there is an issue causing a recursive loop, and the frame execution hits the depth limit, Python will raise a RecursionError which can be handled from a try..except block in Python code. Because pthreads have their own stack size, the max depth of Python and the stack size of the pthread might conflict.
If the thread stack size is smaller than the max frame depth in Python, the entire Python process will crash before a RecursionError is raised. Also, the max depth in Python can be configured at runtime using sys.setrecursionlimit().
To avoid these crashes, the CPython pthread implementation sets the stack size to the pythread_stacksize value of the Interpreter State
Most modern POSIX-compliant Operating Systems support system scheduling of pthreads. If PTHREAD_SYSTEM_SCHED_SUPPORTED is defined in pyconfig.h, the pthread is set to PTHREAD_SCOPE_SYSTEM, meaning that the priority of the thread on the Operating System scheduler is decided against the other threads on the system, not just the ones within the Python process.
Once the thread properties have been configured, the thread is created using the pthread_create() API. This runs the bootstrap function from inside the new thread.
Lastly, the thread handle, pthread_t is cast into an unsigned long and returned to become the thread ID.
Windows Threads
Windows threads implemented in Python/thread_nt.h follow a similar, but simpler pattern. The stack size of the new thread is configured to the interpreter pythread_stacksize value (if set). The thread is created using the _beginthreadex() Windows API using the bootstrap function as the callback.
Lastly, the thread ID is returned.
Conclusion
This was not an exhaustive tutorial on Python threads. Python’s thread implementation is extensive and offers many mechanisms for sharing data between threads, locking objects, and resources.
Threads are a great, efficient way of improving the runtime of your Python applications when they are IO-bound. In this section, you have seen what the GIL is, why it exists and which parts of the standard library may be exempt from its constraints.
Asynchronous Programming
Python offers many ways of accomplishing concurrent programming without using threads or multiprocessing. These features have been added, expanded, and often replaced with better alternatives.
For the target version of this book, 3.9.0b1, the following asynchronous systems are deprecated:
- The
@coroutinedecorator
The following systems are still available:
- Creating futures from
asynckeywords - Coroutines using the
yield fromkeywords
Generators
Python Generators are functions that return a yield statement and can be called continually to generate further values.
Generators are often used as a more memory efficient way of looping through values in a large block of data, like a file, a database, or over a network. Generator objects are returned in place of a value when yield is used instead of return. The generator object is created from the yield statement and returned to the caller.
This simple generator function will yield the letters a-z:
def letters():
i = 97 # letter 'a' in ASCII
end = 97 + 26 # letter 'z' in ASCII
while i < end:
yield chr(i)
i += 1
If you call letters(), it won’t return a value, but instead it returns a generator object:
>>> from letter_generator import letters
>>> letters()
<generator object letters at 0x1004d39b0>
Built into the syntax of the for statement is the ability to iterate through a generator object until it stops yielding values:
>>> for letter in letters():
... print(letter)
a
b
c
d
...
This implementation uses the iterator protocol. Objects that have a __next__()method can be looped over by for and while loops, or using the next() builtin.
All container types (like lists, sets, tuples) in Python implement the iterator protocol. Generators are unique because the implementation of the __next__() method recalls the generator function from its last state. Generators are not executing in the background, they are paused. When you request another value, they resume execution.
Within the generator object structure is the frame object as it was at the last yield statement.
Generator Structure
Generator objects are created by a template macro, PyGenObject_HEAD(prefix).
This macro is used by the following types and prefixes:
PyGenObject-gi_(Generator objects)PyCoroObject-cr_(Coroutine objects)PyAsyncGenObject-ag_(Async generator objects)
You will cover coroutine and async generator objects later in this chapter.
The PyGenObject type has the base properties:
| Field | Type | Purpose |
|---|---|---|
[x]_frame |
PyFrameObject* |
Current frame object for the generator |
[x]_running |
char |
char Set to 0 or 1 if the generator is currently runing |
[x]_code |
PyObject * (PyCodeObject*) |
Compiled function that yielded the generator |
[x]_weakreflist |
PyObject *(list) |
List of weak references to objects inside the generator function |
[x]_name |
PyObject * (str) |
Name of the generator |
[x]_qualname |
PyObject * (str) |
Qualified name of the generator |
[x]_exc_state |
_PyErr_StackItem |
Exception data if the generator call raises an exception |
On top of the base properties, the PyCoroObject type has:
| Field | Type | Purpose |
|---|---|---|
cr_origin |
PyObject * (tuple) |
Tuple containing the originating frame and caller |
On top of the base properties, the PyAsyncGenObject type has:
| Field | Type | Purpose |
|---|---|---|
ag_finalizer |
PyObject * |
Link to the finalizer method |
ag_hooks_inited |
int |
Flag to mark that the hooks have been initialized |
ag_closed |
int |
Flag to mark that the generator is closed |
ag_running_async |
int |
Flag to mark that the generator is running |
Related Source File
Source files related to generators are:
| File | Purpose |
|---|---|
Include/genobject.h |
Generator API and PyGenObject definition |
Objects/genobject.c |
Generator Object implementation |
Creating Generators
When a function containing a yield statement is compiled, the resulting code object has an additional flag, CO_GENERATOR.
In the chapter on the Execution Loop: Constructing Frames, you explored how a compiled code object is converted into a frame object when it is executed. In the process, there is a special case for generators, coroutines, and async generators. The _PyEval_EvalCode() function checks the code object for the CO_GENERATOR, CO_COROUTINE, and CO_ASYNC_GENERATOR flags.
Instead of evaluation a code object inline, the frame is created and turned into a Generator, Coroutine or Async Generator Object. A coroutine is created using PyCoro_New(), an async generator is created with PyAsyncGen_New(), and a generator with PyGen_NewWithQualName():
PyObject *
_PyEval_EvalCode(PyObject *_co, PyObject *globals, PyObject *locals, ...
...
/* Handle generator/coroutine/asynchronous generator */
if (co->co_flags & (CO_GENERATOR | CO_COROUTINE | CO_ASYNC_GENERATOR)) {
PyObject *gen;
PyObject *coro_wrapper = tstate->coroutine_wrapper;
int is_coro = co->co_flags & CO_COROUTINE;
...
/* Create a new generator that owns the ready to run frame
* and return that as the value. */
if (is_coro) {
>>> gen = PyCoro_New(f, name, qualname);
} else if (co->co_flags & CO_ASYNC_GENERATOR) {
>>> gen = PyAsyncGen_New(f, name, qualname);
} else {
>>> gen = PyGen_NewWithQualName(f, name, qualname);
}
...
return gen;
}
...
The generator factory, PyGen_NewWithQualName(), takes the frame and completes some steps to populate the generator object fields:
- Sets the gi_code property to the compiled code object
- Sets the generator to not running (
gi_running = 0) - Sets the exception and weakref lists to
NULL
You can also see that gi_code is the compiled code object for the generator function by importing the dis module and disassembling the bytecode inside:
>>> from letter_generator import letters
>>> gen = letters()
>>> import dis
>>> dis.disco(gen.gi_code)
2 0 LOAD_CONST 1 (97)
2 STORE_FAST 0 (i)
...
In the chapter on the Evaluation Loop, you explored the Frame Object Type. Frame objects contain locals and globals, the last executed instructions, and the code to be executed.
The builtin behavior and state of the frame object are how generators can pause and be resumed on demand.
Executing Generators
Whenever __next__() is called on a generator object, gen_iternext() is called with the generator instance, which immediately calls gen_send_ex() inside Objects/genobject.c.
gen_send_ex() is the function that converts a generator object into the next yielded result. You’ll see many similarities with the way frames are constructed from a code object as these functions have similar tasks.
The gen_send_ex() function is shared with generators, coroutines, and async generators and has the following steps:
- The current thread state is fetched
- The frame object from the generator object is fetched
- If the generator is running when
__next__()was called, raise aValueError - If the frame inside the generator is at the top of the stack:
- In the case of a coroutine, if the coroutine is not already marked as closing, a
RuntimeErroris raised - If this is an async generator, raise a
StopAsyncIteration - For a standard generator, a
StopIterationis raised.
- In the case of a coroutine, if the coroutine is not already marked as closing, a
- If the last instruction in the frame (
f->f_lasti) is still -1 because it has just been started, and this is a coroutine or async generator, then a non-None value can’t be passed as an argument, so an exception is raised - Else, this is the first time it’s being called, and arguments are allowed. The value of the argument is pushed to the frame’s value stack
- The
f_backfield of the frame is the caller to which return values are sent, so this is set to the current frame in the thread. This means that the return value is sent to the caller, not the creator of the generator - The generator is marked as running
- The last exception in the generator’s exception info is copied from the last exception in the thread state
- The thread state exception info is set to the address of the generator’s exception info. This means that if the caller enters a breakpoint around the execution of a generator, the stack trace goes through the generator and the offending code is clear
- The frame inside the generator is executed within the
Python/ceval.cmain execution loop, and the value returned - The thread state last exception is reset to the value before the frame was called
- The generator is marked as not running
- The following cases then match the return value and any exceptions thrown by the call to the generator. Remember that generators should raise a
StopIterationwhen they are exhausted, either manually, or by not yielding a value. Coroutines and async generators should not:- If no result was returned from the frame, raise a
StopIterationfor generators andStopAsyncIterationfor async generators - If a
StopIterationwas explicitly raised, but this is a coroutine or an async generator, raise aRuntimeErroras this is not allowed - If a
StopAsyncIterationwas explicitly raised and this is an async generator, raise aRuntimeError, as this is not allowed
- If no result was returned from the frame, raise a
- Lastly, the result is returned back to the caller of
__next__()
Bringing this all together, you can see how the generator expression is a powerful syntax where a single keyword, yield triggers a whole flow to create a unique object, copy a compiled code object as a property, set a frame, and store a list of variables in the local scope.
Coroutines
Generators have a big limitation. They can only yield values to their immediate caller. An additional syntax was added to Python to overcome this the yield from statement. Using this syntax, you can refactor generators into utility functions and then yield from them.
For example, the letter generator can be refactored into a utility function where the starting letter is an argument. Using yield from, you can choose which generator object to return:
def gen_letters(start, x):
i = start
end = start + x
while i < end:
yield chr(i)
i += 1
def letters(upper):
if upper:
yield from gen_letters(65, 26) # A-Z
else:
yield from gen_letters(97, 26) # a-z
for letter in letters(False):
# Lower case a-z
print(letter)
for letter in letters(True):
# Upper case A-Z
print(letter)
Generators are also great for lazy sequences, where they can be called multiple times. Building on the behaviors of generators, such as being able to pause and resume execution, the concept of a coroutine was iterated in Python over multiple APIs. Generators are a limited form of coroutine because you can send data to them using the .send() method.
It is possible to send messages bi-directionally between the caller and the target. Coroutines also store the caller in the cr_origin attribute.
Coroutines were initially available via a decorator, but this has since been deprecated in favor of “native” coroutines using the keywords async and await.
To mark that a function returns a coroutine, it must be preceded with the async keyword. The async keyword makes it explicit (unlike generators) that this function returns a coroutine and not a value.
To create a coroutine, define a function with the keyword async def. In this example, add a timer using the asyncio.sleep() function and return a wake-up string:
>>> import asyncio
>>> async def sleepy_alarm(time):
... await asyncio.sleep(time)
... return "wake up!"
>>> alarm = sleepy_alarm(10)
>>> alarm
<coroutine object sleepy_alarm at 0x1041de340>
When you call the function, it returns a coroutine object. There are many ways to execute a coroutine. The easiest is using asyncio.run(coro).
Run asyncio.run() with your coroutine object, then after 10 seconds it will sound the alarm:
>>> asyncio.run(alarm)
'wake up'
So far, there is a small benefit over a regular function. The benefit of coroutines is that you can run them concurrently. Because the coroutine object is a variable that you can pass to a function, these objects can be linked together and chained, or created in a sequence.
For example, if you wanted to have 10 alarms with different intervals and start them all at the same time, these coroutine objects can be converted into tasks.
The task API is used to schedule and execute multiple coroutines concurrently. Before tasks are scheduled, an event loop must be running. The job of the event loop is to schedule concurrent tasks and connect events such as completion, cancellation, and exceptions with callbacks. When you called asyncio.run(), the run function (in Lib/asyncio/runners.py) did these tasks for you:
- Started a new event loop
- Wrapped the coroutine object in a task
- Set a callback on the completion of the task
- Looped over the task until it completed
- Returned the result
Related Source Files
Source files related to coroutines are:
| File | Purpose |
|---|---|
Lib/asyncio |
Python standard library implementation for asyncio |
Event Loops
Event loops are the glue that holds async code together. Written in pure Python, event loops are an object containing tasks. When started, a loop can either run once or run forever. Any of the tasks in the loop can have callbacks. The loop will run the callbacks if a task completes or fails.
loop = asyncio.new_event_loop()
Inside a loop is a sequence of tasks, represented by the type asyncio.Task, tasks are scheduled onto a loop, then once the loop is running, it loops over all the tasks until they complete.
You can convert the single timer into a task loop:
import asyncio
async def sleepy_alarm(person, time):
await asyncio.sleep(time)
print(f"{person} -- wake up!")
async def wake_up_gang():
tasks = [
asyncio.create_task(sleepy_alarm("Bob", 3), name="wake up Bob"),
asyncio.create_task(sleepy_alarm("Sanjeet", 4), name="wake up Sanjeet"),
asyncio.create_task(sleepy_alarm("Doris", 2), name="wake up Doris"),
asyncio.create_task(sleepy_alarm("Kim", 5), name="wake up Kim")
]
await asyncio.gather(*tasks)
asyncio.run(wake_up_gang())
This will print:
Doris -- wake up!
Bob -- wake up!
Sanjeet -- wake up!
Kim -- wake up!
In the event loop, it will run over each of the coroutines to see if they are completed. Similar to how the yield keyword can return multiple values from the same frame, the await keyword can return multiple states. The event loop will execute the sleepy_alarm() coroutine objects again and again until the await asyncio.sleep() yields a completed result, and the print() function is able to execute.
For this to work, asyncio.sleep() must be used instead of the blocking (and not async-aware) time.sleep().
Example
You can convert the multithreaded port scanner example to asyncio with these steps:
- Change the
check_port()function to use a socket connection fromasyncio.open_connection(), which creates a future instead of an immediate connection - Use the socket connection future in a timer event, with
asyncio.wait_for() - Append the port to the results list if succeeded
- Add a new function,
scan()to create thecheck_port()coroutines for each port and add them to a list,tasks - Merge all the tasks into a new coroutine using
asyncio.gather() - Run the scan using
asyncio.run()
import time
import asyncio
timeout = 1.0
async def check_port(host: str, port: int, results: list):
try:
future = asyncio.open_connection(host=host, port=port)
r, w = await asyncio.wait_for(future, timeout=timeout)
results.append(port)
w.close()
except asyncio.TimeoutError:
pass # port is closed, skip-and-continue
async def scan(start, end, host):
tasks = []
results = []
for port in range(start, end):
tasks.append(check_port(host, port, results))
await asyncio.gather(*tasks)
return results
if __name__ == '__main__':
start = time.time()
host = "localhost" # pick a host you own
results = asyncio.run(scan(80, 100, host))
for result in results:
print("Port {0} is open".format(result))
print("Completed scan in {0} seconds".format(time.time() - start))
Finally, this scan completes in just over 1 second:
python portscanner_async.py
Port 80 is open
Completed scan in 1.0058400630950928 seconds
Asynchronous Generators
The concepts you have learned so far, generators and coroutines can be combined into a type - asynchronous generators. If a function is declared with both the async keyword and it contains a yield statement, it is converted into an async generator object when called. Like generators, async generators must be executed by something that understands the protocol. In place of __next__(), async generators have a method __anext__(). A regular for loop would not understand an async generator, so instead, the async for statement is used.
You can refactor the check_port() function into an async generator that yields the next open port until it hits the last port, or it has found a specified number of open ports:
async def check_ports(host: str, start: int, end: int, max=10):
found = 0
for port in range(start, end):
try:
future = asyncio.open_connection(host=host, port=port)
r, w = await asyncio.wait_for(future, timeout=timeout)
yield port
found += 1
w.close()
if found >= max:
return
except asyncio.TimeoutError:
pass # closed
To execute this, use the async for statement:
async def scan(start, end, host):
results = []
async for port in check_ports(host, start, end, max=1):
results.append(port)
return results
Subinterpreters
So far, you have covered:
- Parallel execution with multiprocessing
- Concurrent execution with threads and async
The downside of multiprocessing is that the inter-process communication using pipes and queues is slower than shared memory. Also the overhead to start a new process is significant.
Threading and async have small overhead but don’t offer truly parallel execution because of the thread-safety guarantees in the GIL. The fourth option is subinterpreters, which have a smaller overhead than multiprocessing, and allow a GIL per subinterpreter. After all, it is the Global Interpreter Lock. Within the CPython runtime, there is always 1 interpreter. The interpreter holds the interpreter state, and within an interpreter, you can have 1 or many Python threads. The interpreter is the container for the evaluation loop. the interpreter also manages its own memory, reference counter, and garbage collection. CPython has low-level C APIs for creating interpreters, like the Py_NewInterpreter().
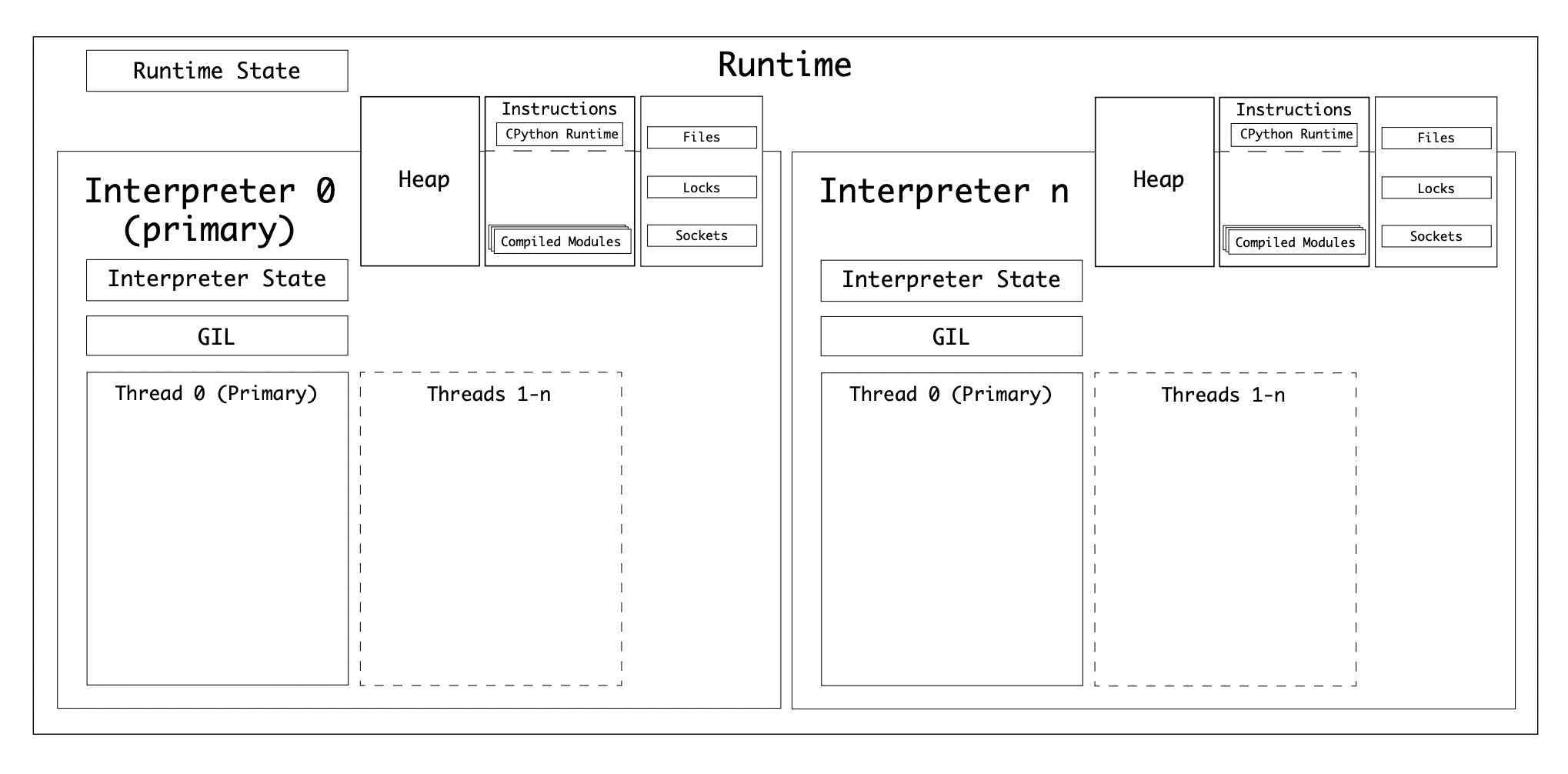
Note
The subinterpreters module is still experimental in 3.9.0b1, so the API is subject to change and the implementation is still buggy.
Because Interpreter state contains the memory allocation arena, a collection of all pointers to Python objects (local and global), subinterpreters cannot access the global variables of other interpreters. Similar to multiprocessing, to share objects between interpreters you must serialize them, or use ctypes, and use a form of IPC (network, disk or shared memory).
Related Source Files
Source files related to subinterpreters are:
| File | Purpose |
|---|---|
Lib/_xxsubinterpreters.c |
C implementation of the subinterpreters module |
Python/pylifecycle.c |
C implementation of the interpreter management API |
Example
In the final example application, the actual connection code has to be captured in a string. In 3.9.0b1, subinterpreters can only be executed with a string of code.
To start each of the subinterpreters, a list of threads is started, with a callback to a function, run().
This function will:
- Create a communication channel
- Start a new subinterpreter
- Send it the code to execute
- Receive data over the communication channel
- If the port connection succeeded, add it to the thread-safe queue
import time
import _xxsubinterpreters as subinterpreters
from threading import Thread
import textwrap as tw
from queue import Queue
timeout = 1 # in seconds..
def run(host: str, port: int, results: Queue):
# Create a communication channel
channel_id = subinterpreters.channel_create()
interpid = subinterpreters.create()
subinterpreters.run_string(
interpid,
tw.dedent(
"""
import socket; import _xxsubinterpreters as subinterpreters
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
subinterpreters.channel_send(channel_id, result)
sock.close()
"""),
shared=dict(
channel_id=channel_id,
host=host,
port=port,
timeout=timeout
))
output = subinterpreters.channel_recv(channel_id)
subinterpreters.channel_release(channel_id)
if output == 0:
results.put(port)
if __name__ == '__main__':
start = time.time()
host = "127.0.0.1" # pick a host you own
threads = []
results = Queue()
for port in range(80, 100):
t = Thread(target=run, args=(host, port, results))
t.start()
threads.append(t)
for t in threads:
t.join()
while not results.empty():
print("Port {0} is open".format(results.get()))
print("Completed scan in {0} seconds".format(time.time() - start))
Because of the reduced overheads compared with multiprocessing, this example should execute 30-40% faster and with fewer memory resources:
python portscanner_subinterpreters.py
Port 80 is open
Completed scan in 1.3474230766296387 seconds
Conclusion
Congratulations on getting through the biggest chapter in the book! You’ve covered a lot of ground. Let us recap some of the concepts and their applications.
For truly parallel execution, you need multiple CPUs or cores. You also need to use either multiprocessing or subinterpreters packages so that the Python interpreter can be executed in parallel. Remember that startup time is significant, and each interpreter has a big memory overhead. If the tasks that you want to execute are shortlived, use a pool of workers and a queue of tasks.
If you have multiple IO-bound tasks and want them to run concurrently, you should use multithreading, or use coroutines with the asyncio package.
All four of these approaches require an understanding of how to safely and efficiently transfer data between processes or threads. The best way to reinforce what you’ve learned is to look at an application you’ve written and seen how it can be refactored to leverage these techniques.